Elasticsearch-database
Elasticsearch is een van de meest populaire NoSQL-databases die wordt gebruikt om op tekst gebaseerde gegevens op te slaan en te zoeken. Het is gebaseerd op de Lucene-indexeringstechnologie en maakt zoeken in milliseconden mogelijk op basis van geïndexeerde gegevens.
Op basis van de Elasticsearch-website is hier de definitie:
Elasticsearch is een open source gedistribueerde, RESTful zoek- en analyse-engine die in staat is een groeiend aantal use-cases op te lossen.
Dat waren enkele hoogstaande woorden over Elasticsearch. Laten we de concepten hier in detail begrijpen.
- Verdeeld: Elasticsearch verdeelt de gegevens die het bevat in meerdere knooppunten en gebruikt meester-slaaf algoritme intern
- RUSTIG: Elasticsearch ondersteunt databasequery's via REST API's. Dit betekent dat we eenvoudige HTTP-aanroepen kunnen gebruiken en HTTP-methoden kunnen gebruiken zoals GET, POST, PUT, DELETE enz. om toegang te krijgen tot gegevens.
- Zoek- en analyse-engine: ES ondersteunt zeer analytische zoekopdrachten die in het systeem kunnen worden uitgevoerd en die kunnen bestaan uit geaggregeerde zoekopdrachten en meerdere typen, zoals gestructureerde, ongestructureerde en geografische zoekopdrachten.
- Horizontaal schaalbaar: Dit soort schaalvergroting verwijst naar het toevoegen van meer machines aan een bestaand cluster. Dit betekent dat ES in staat is meer knooppunten in zijn cluster te accepteren en geen uitvaltijd biedt voor vereiste upgrades van het systeem. Bekijk de onderstaande afbeelding om de schaalconcepten te begrijpen:
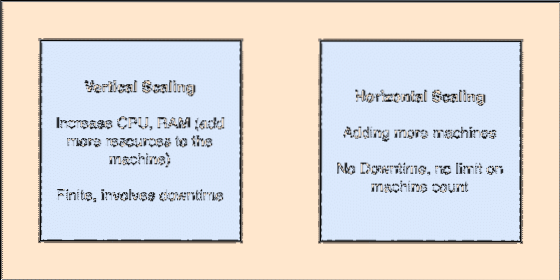
Verticale en horizontale schaalvergroting
Aan de slag met Elasticsearch-database
Om Elasticsearch te gaan gebruiken, moet het op de machine zijn geïnstalleerd. Lees hiervoor ElasticSearch installeren op Ubuntu.
Zorg ervoor dat je een actieve ElasticSearch-installatie hebt als je voorbeelden wilt proberen die we later in de les presenteren.
Elasticsearch: concepten en componenten
In deze sectie zullen we zien welke componenten en concepten de kern vormen van Elasticsearch. Inzicht in deze concepten is belangrijk om te begrijpen hoe ES werkt:
- TROS: Een cluster is een verzameling servermachines (knooppunten) die de gegevens bevatten holds. De gegevens worden verdeeld over meerdere knooppunten zodat ze kunnen worden gerepliceerd en Single Point of Failure (SPoF) niet gebeurt met de ES-server. Standaardnaam van het cluster is elastisch zoeken. Elk knooppunt in een cluster maakt verbinding met het cluster met een URL en de clusternaam, dus het is belangrijk om deze naam duidelijk en duidelijk te houden.
- Knooppunt: Een Node-machine maakt deel uit van een server en wordt een enkele machine genoemd. Het slaat de gegevens op en biedt indexerings- en zoekmogelijkheden, samen met andere knooppunten voor het cluster.
Vanwege het concept van horizontale schaling kunnen we virtueel een oneindig aantal knooppunten toevoegen aan een ES-cluster om het veel meer kracht en indexeringsmogelijkheden te geven.
- Inhoudsopgave: Een Index is een verzameling documenten met enigszins vergelijkbare kenmerken. Een index lijkt veel op een database in een op SQL gebaseerde omgeving.
- Type: Een Type wordt gebruikt om gegevens tussen dezelfde index te scheiden. Klantendatabase/index kan bijvoorbeeld meerdere typen hebben, zoals gebruiker, betalingstype, enz.
Merk op dat typen zijn verouderd vanaf ES v6.0.vanaf 0. Lees hier waarom dit is gedaan.
- Document: Een document is het laagste eenheidsniveau dat gegevens vertegenwoordigt. Stel je het voor als een JSON-object dat je gegevens bevat. Het is mogelijk om zoveel documenten in een Index te indexeren.
Soorten zoekopdrachten in Elasticsearch
Elasticsearch staat bekend om zijn bijna realtime zoekmogelijkheden en de flexibiliteit die het biedt met het type gegevens dat wordt geïndexeerd en doorzocht. Laten we beginnen met het bestuderen van het gebruik van zoeken met verschillende soorten gegevens.
- Gestructureerd zoeken: dit type zoekopdracht wordt uitgevoerd op gegevens met een vooraf gedefinieerde indeling, zoals datums, tijden en getallen. Met een vooraf gedefinieerd formaat komt de flexibiliteit van het uitvoeren van algemene bewerkingen, zoals het vergelijken van waarden in een reeks datums. interessant genoeg, tekstuele gegevens kunnen ook gestructureerd worden. Dit kan gebeuren wanneer een veld een vast aantal waarden heeft. Naam van databases kan bijvoorbeeld zijn, MySQL, MongoDB, Elasticsearch, Neo4J enz. Met gestructureerd zoeken is het antwoord op de zoekopdrachten die we uitvoeren een ja of nee.
- Zoeken in volledige tekst: dit type zoekopdracht is afhankelijk van twee belangrijke factoren:, Relevantie en Analyse. Met Relevantie bepalen we hoe goed sommige gegevens overeenkomen met de zoekopdracht door een score te definiëren voor de resulterende documenten. Deze score wordt door ES zelf gegeven. Analyse verwijst naar het opsplitsen van de tekst in genormaliseerde tokens om een omgekeerde index te maken.
- Zoeken in meerdere velden: Nu het aantal analytische zoekopdrachten steeds groter wordt op de opgeslagen gegevens in ES, hebben we meestal niet alleen te maken met eenvoudige zoekvragen. Er zijn steeds meer eisen gesteld aan het uitvoeren van query's die zich over meerdere velden uitstrekken en waarbij een gesorteerde lijst met gescoorde gegevens door de database zelf aan ons wordt geretourneerd. Op deze manier kunnen data op een veel efficiëntere manier bij de eindgebruiker aanwezig zijn.
- Proimity Matching: Query's zijn tegenwoordig veel meer dan alleen identificeren of sommige tekstuele gegevens een andere string bevatten of niet. Het gaat om het leggen van de relatie tussen gegevens, zodat deze kunnen worden gescoord en gematcht met de context waarin gegevens worden gematcht. Bijvoorbeeld:
- Bal geraakt John
- John raakte de bal
- John kocht een nieuwe bal die de tuin van Jaen raakte
Een matchquery vindt alle drie de documenten wanneer ernaar wordt gezocht bal geraakt. Een zoekactie in de buurt kan ons vertellen hoe ver deze twee woorden in dezelfde regel of alinea voorkomen waardoor ze overeenkwamen.
- Gedeeltelijke matching: het is vaak nodig om gedeeltelijke matchin-query's uit te voeren. Gedeeltelijke overeenkomst stelt ons in staat om zoekopdrachten uit te voeren die gedeeltelijk overeenkomen. Laten we, om dit te visualiseren, eens kijken naar vergelijkbare SQL-query's:
SQL-query's: gedeeltelijke overeenkomst
WAAR naam LIKE "%john%"
EN naam LIKE "%red%"
EN noem LIKE "%garden%"In sommige gevallen hoeven we alleen gedeeltelijke match-query's uit te voeren, zelfs als ze kunnen worden beschouwd als brute-force-technieken.
Integratie met Kibana
Als het gaat om een analyse-engine, moeten we meestal analysequery's uitvoeren in een Business-Intelligence (BI)-domein. Als het gaat om bedrijfsanalisten of gegevensanalisten, zou het niet eerlijk zijn om aan te nemen dat mensen een programmeertaal kennen wanneer ze gegevens in ES Cluster willen visualiseren. Dit probleem wordt opgelost door Kibana. Kibana biedt zoveel voordelen voor BI dat mensen gegevens daadwerkelijk kunnen visualiseren met een uitstekend, aanpasbaar dashboard en gegevens op een onaantrekkelijke manier kunnen bekijken. Laten we eens kijken naar enkele van de voordelen ervan.
Interactieve grafieken
De kern van Kibana zijn interactieve grafieken zoals deze: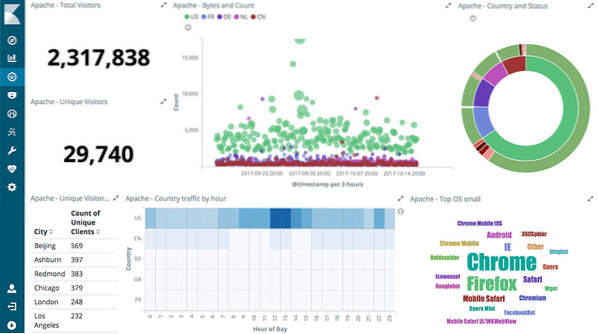
Kibana wordt ondersteund met verschillende soorten grafieken zoals cirkeldiagrammen, zonnestralen, histogrammen en nog veel meer die gebruik maken van de volledige aggregatiemogelijkheden van ES.
Ondersteuning voor kaarten
Kibana ondersteunt ook volledige geo-aggregatie waarmee we onze gegevens kunnen geo-kaarten. Is dit niet cool?!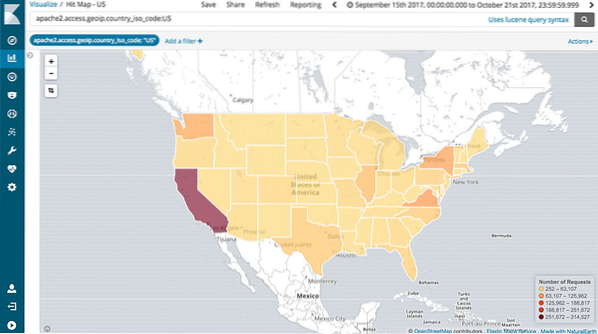
Vooraf gemaakte aggregaties en filters
Met vooraf gebouwde aggregaties en filters is het mogelijk om zeer geoptimaliseerde zoekopdrachten letterlijk te fragmenteren, te laten vallen en uit te voeren binnen het Kibana-dashboard. Met slechts een paar klikken is het mogelijk om geaggregeerde zoekopdrachten uit te voeren en resultaten te presenteren in de vorm van interactieve grafieken.
Eenvoudige distributie van dashboards
Met Kibana is het ook heel eenvoudig om dashboards te delen met een veel breder publiek zonder wijzigingen aan het dashboard aan te brengen met behulp van de modus Alleen dashboard. We kunnen eenvoudig dashboards invoegen in onze interne wiki of webpagina's.
Feature-afbeeldingen uit de Kibana-productpagina:.
Elasticsearch gebruiken
Voer de volgende opdracht uit om de instantiedetails en de clusterinformatie te zien: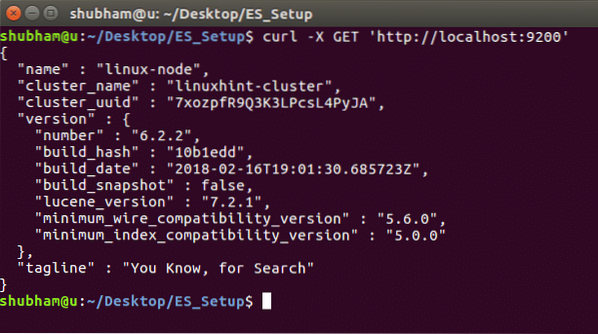
Nu kunnen we proberen wat gegevens in ES in te voegen met behulp van de volgende opdracht:
Gegevens invoegen
krullen \-X POST 'http://localhost:9200/linuxhint/hello/1' \
-H 'Inhoudstype: applicatie /json' \
-d ' "naam" : "LinuxHint" '\
Dit is wat we terugkrijgen met deze opdracht:
Laten we proberen de gegevens nu op te halen:
Gegevens ophalen
curl -X GET 'http://localhost:9200/linuxhint/hello/1'Wanneer we deze opdracht uitvoeren, krijgen we de volgende uitvoer:
Conclusie
In deze les hebben we gekeken hoe we ElasticSearch kunnen gaan gebruiken, een uitstekende Analytics-engine die ook uitstekende ondersteuning biedt voor bijna realtime zoeken in vrije tekst.


