Panda's DataFrame is een 2D (tweedimensionaal) geannoteerde datastructuur waarin gegevens in tabelvorm worden uitgelijnd met verschillende rijen en kolommen. Voor een beter begrip gedraagt het DataFrame zich als een spreadsheet die drie verschillende componenten bevat: index, kolommen en gegevens. Panda's DataFrames zijn de meest gebruikelijke manier om de objecten van de panda te gebruiken.
Panda's DataFrames kunnen op verschillende manieren worden gemaakt. Dit artikel legt alle mogelijke methoden uit waarmee u Pandas DataFrame in python kunt maken. We hebben alle voorbeelden op de pycharm-tool uitgevoerd. Laten we beginnen met de implementatie van elke methode één voor één.
Basissyntaxis
Volg de volgende syntaxis bij het maken van DataFrames in Pandas Python:
pd.DataFrame(Df_data)Voorbeeld:Laten we het uitleggen met een voorbeeld. In dit geval hebben we de gegevens van de namen en percentages van studenten opgeslagen in een 'Students_Data'-variabele. Verder, met behulp van de pd.DataFrame (), we hebben een DataFrames gemaakt om het resultaat van de student weer te geven.
panda's importeren als pdStudenten_Data =
'Naam':['Samreena', 'Asif', 'Mahwish', 'Raees'],
'Percentage':[90,80,70,85]
resultaat = pd.DataFrame(Students_Data)
afdrukken (resultaat)
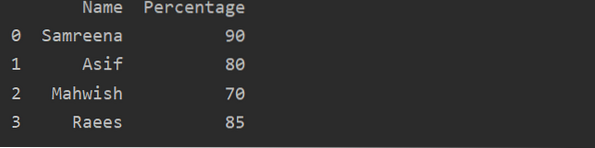
Methoden om Panda's DataFrames te maken
Panda's DataFrames kunnen worden gemaakt met behulp van de verschillende manieren die we in de rest van het artikel zullen bespreken. We zullen het resultaat van de cursussen van de student afdrukken in de vorm van DataFrames. Met een van de volgende methoden kunt u dus vergelijkbare DataFrames maken die in de volgende afbeelding worden weergegeven:
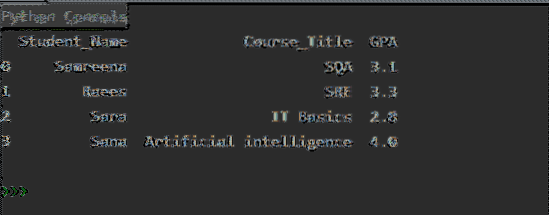
Methode # 01: Panda's DataFrame maken uit het woordenboek met lijsten
In het volgende voorbeeld worden DataFrames gemaakt op basis van de woordenboeken van lijsten met betrekking tot cursusresultaten van studenten. Importeer eerst de bibliotheek van een panda en maak vervolgens een woordenboek met lijsten. De dicteersleutels vertegenwoordigen de kolomnamen zoals 'Student_Name', 'Course_Title' en 'GPA'. Lijsten vertegenwoordigen de gegevens of inhoud van de kolom. De variabele 'dictionary_lists' bevat de gegevens van studenten die verder zijn toegewezen aan de variabele 'df1'. Gebruik de printopdracht om de volledige inhoud van DataFrames af te drukken.
Voorbeeld:
# Importeer bibliotheken voor panda's en numpypanda's importeren als pd
# Panda's bibliotheek importeren
panda's importeren als pd
# Maak een woordenboek van lijst
woordenboek_lists =
'Student_Name': ['Samreena', 'Raees', 'Sara', 'Sana'],
'Course_Title': ['SQA','SRE','IT Basics', 'Kunstmatige intelligentie'],
'GPA': [3.1, 3.3, 2.8, 4.0]
# Maak het DataFrame
dframe = pd.DataFrame(woordenboek_lijsten)
print(dframe)
Na het uitvoeren van de bovenstaande code, wordt de volgende uitvoer weergegeven:
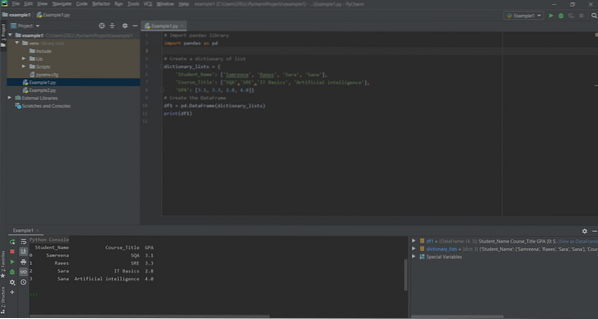
Methode # 02: Maak Pandas DataFrame uit het woordenboek van NumPy-array
Het DataFrame kan worden gemaakt op basis van het dict van array/list. Voor dit doel moet de lengte hetzelfde zijn als alle narray. Als er een index wordt doorgegeven, moet de lengte van de index gelijk zijn aan de lengte van de array. Als er geen index wordt doorgegeven, is in dit geval de standaardindex een bereik (n). Hier staat n voor de lengte van de array.
Voorbeeld:
importeer numpy als np# Maak een numpy-array
nparray = np.reeks(
[['Samreena', 'Raees', 'Sara', 'Sana'],
['SQA', 'SRE', 'IT Basics', 'Artificiële Intelligentie'],
[3.1, 3.3, 2.8, 4.0]])
# Maak een woordenboek van nparray
woordenboek_of_nparray =
'Student_Name': nparray[0],
'Course_Title': nparray[1],
'GPA': nparray[2]
# Maak het DataFrame
dframe = pd.DataFrame(woordenboek_van_nparray)
print(dframe)

Methode # 03: Panda's DataFrame maken met behulp van de lijst met lijsten
In de volgende code vertegenwoordigt elke regel een enkele rij:.
Voorbeeld:
# Importeer bibliotheek Panda's pdpanda's importeren als pd
# Maak een lijst met lijsten
group_lists = [
['Samreena', 'SQA', 3.1],
['Raees', 'SRE', 3.3],
['Sara', 'IT Basics', 2.8],
['Sana', 'Kunstmatige Intelligentie', 4.0]]
# Maak het DataFrame
dframe = pd.DataFrame(group_lists, columns = ['Student_Name', 'Course_Title', 'GPA'])
print(dframe)

Methode # 04: Panda's DataFrame maken met behulp van de lijst met woordenboek
In de volgende code vertegenwoordigt elk woordenboek een enkele rij en sleutels die de kolomnamen vertegenwoordigen.
Voorbeeld:
# Bibliotheekpanda's importerenpanda's importeren als pd
# Maak een lijst met woordenboeken
dict_list = [
'Student_Name': 'Samreena', 'Course_Title': 'SQA', 'GPA': 3.1,
'Student_Name': 'Raees', 'Course_Title': 'SRE', 'GPA': 3.3,
'Student_Name': 'Sara', 'Course_Title': 'IT Basics', 'GPA': 2.8,
'Student_Name': 'Sana', 'Course_Title': 'Kunstmatige intelligentie', 'GPA': 4.0]
# Maak het DataFrame
dframe = pd.DataFrame(dict_list)
print(dframe)

Methode # 05: panda's-dataframe maken van dict of panda-serie
De dicteertoetsen vertegenwoordigen de namen van kolommen en elke serie vertegenwoordigt de kolominhoud. In de volgende regels code hebben we drie soorten series genomen: Name_series, Course_series en GPA_series.
Voorbeeld:
# Bibliotheekpanda's importerenpanda's importeren als pd
# Maak de reeks studentennamen
Naam_serie = pd.Serie(['Samreena', 'Raees', 'Sara', 'Sana'])
Course_series = pd.Series(['SQA', 'SRE', 'IT Basics', 'Artificiële intelligentie'])
GPA_series = pd.Serie([3.1, 3.3, 2.8, 4.0])
# Maak een seriewoordenboek
woordenboek_of_nparray
\
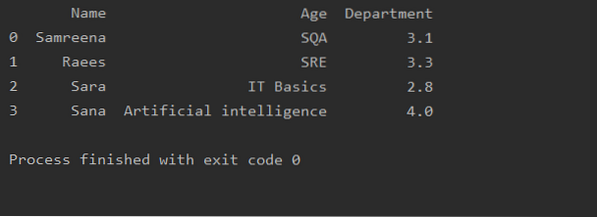
'] = 'Naam': Naam_serie, 'Leeftijd': Cursus_serie, 'Afdeling': GPA_serie
# DataFrame creatie
dframe = pd.DataFrame(woordenboek_van_nparray)
print(dframe)
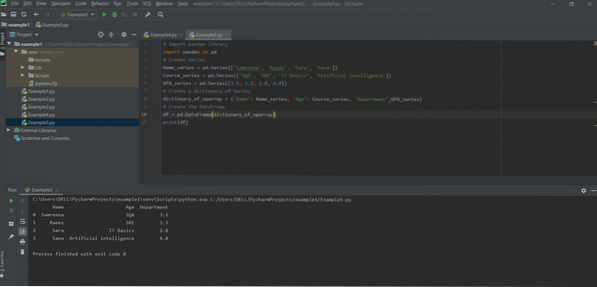
Methode # 06: Pandas DataFrame maken met de functie zip().
Verschillende lijsten kunnen worden samengevoegd via de functie list(zip()). In het volgende voorbeeld worden panda's DataFrame gemaakt door pd . aan te roepen.DataFrame() functie. Er worden drie verschillende lijsten gemaakt die zijn samengevoegd in de vorm van tupels.
Voorbeeld:
panda's importeren als pd# Lijst1
Student_Name = ['Samreena', 'Raees', 'Sara', 'Sana']
# Lijst2
Course_Title = ['SQA', 'SRE', 'IT Basics', 'Artificial Intelligence']
# Lijst3
GPA = [3.1, 3.3, 2.8, 4.0]
# Neem de lijst met tupels uit drie lijsten verder, voeg ze samen met behulp van zip().
tuples = list(zip(Student_Name, Course_Title, GPA))
# Wijs gegevenswaarden toe aan tupels.
tupels
# Tupellijst converteren naar panda's Dataframe.
dframe = pd.DataFrame(tuples, columns=['Student_Name', 'Course_Title', 'GPA'])
# Gegevens afdrukken.
print(dframe)
Conclusie
Met behulp van de bovenstaande methoden kunt u Pandas DataFrames maken in python. We hebben de GPA van een studentencursus afgedrukt door Pandas DataFrames te maken. Hopelijk krijgt u nuttige resultaten na het uitvoeren van de bovengenoemde voorbeelden. Alle programma's zijn goed becommentarieerd voor een beter begrip. Als je meer manieren hebt om Panda's DataFrames te maken, aarzel dan niet om ze met ons te delen. Bedankt voor het lezen van deze tutorial.


