Python bevat een module met de naam urllib voor het afhandelen van Uniform Resource Locator (URL)-gerelateerde taken. Deze module is standaard geïnstalleerd in Python 3 en haalt URL's van verschillende protocollen op via de urlopen() functie. Urllib kan voor veel doeleinden worden gebruikt, zoals het lezen van website-inhoud, het doen van HTTP- en HTTPS-verzoeken, het verzenden van verzoekheaders en het ophalen van responsheaders. De urllib module bevat veel andere modules voor het werken met URL's, zoals: urllib.verzoek, urllib.ontleden, en urllib.fout, onder andere. Deze tutorial laat je zien hoe je de Urllib-module in Python gebruikt.
Voorbeeld 1: URL's openen en lezen met urllib.verzoek
De urllib.verzoek module bevat de klassen en methoden die nodig zijn om elke URL te openen en te lezen. Het volgende script laat zien hoe te gebruiken urllib.verzoek module om een URL te openen en de inhoud van de URL te lezen. Hier de urlopen() methode wordt gebruikt om de URL te openen, “https://www.linuxhint.com/.” Als de URL geldig is, wordt de inhoud van de URL opgeslagen in de objectvariabele met de naam reactie. De lezen() methode van de reactie object wordt vervolgens gebruikt om de inhoud van de URL te lezen.
#!/usr/bin/env python3# Importverzoekmodule van urllib
urllib importeren.verzoek
# Open de specifieke URL om te lezen met urlopen()
response = urllib.verzoek.urlopen('https://www.linuxhint.com/')
# Print de responsgegevens van de URL
print("De uitvoer van de URL is:\n\n",response.lezen())
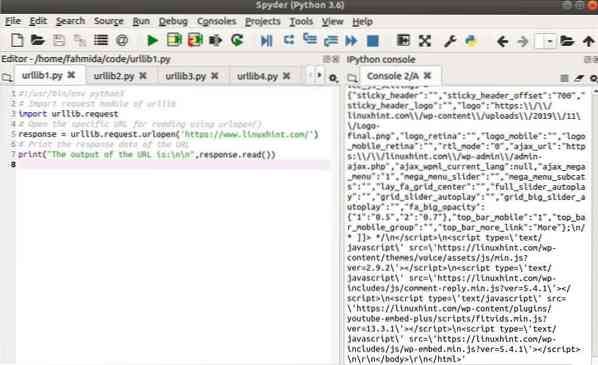
Uitgang:
De volgende uitvoer zal verschijnen na het uitvoeren van het script:.
Voorbeeld 2: Parseren en ontleden van URL's met urllib.ontleden
De urllib.ontleden module wordt voornamelijk gebruikt om de verschillende componenten van een URL te splitsen of samen te voegen. Het volgende script toont verschillende toepassingen van de urllib.ontleden module. De vier functies van urllib.ontleden gebruikt in het volgende script omvatten: urlparse, urlunparse, urlsplit, en urlunsplit. De urlparse module werkt als: urlsplit, en de urlunparse module werkt als: urlunsplit. Er is slechts één verschil tussen deze functies; dat is, urlparse en urlunparse een extra parameter bevatten met de naam 'params' voor splitsen en de samenvoegfunctie. Hier de URL 'https://linuxhint'.com/play_sound_python/' wordt gebruikt voor het splitsen en samenvoegen van de URL.
#!/usr/bin/env python3# Importeer de ontledingsmodule van urllib
urllib importeren.ontleden
# Parseren van URL met urlparse()
urlParse = urllib.ontleden.urlparse('https://linuxhint.com/play_sound_python/')
print("\nDe uitvoer van de URL na het ontleden:\n", urlParse)
# Deelnemen aan URL met behulp van urlunparse()
urlUnparse = urllib.ontleden.urlunparse(urlParse)
print("\nDe samengevoegde uitvoer van het parseren van URL:\n", urlUnparse)
# Parseren van URL met urlsplit()
urlSplit = urllib.ontleden.urlsplit('https://linuxhint.com/play_sound_python/')
print("\nDe uitvoer van de URL na het splitsen:\n", urlSplit)
# Deelnemen aan URL met behulp van urlunsplit()
urlUnsplit = urllib.ontleden.urlunsplit(urlSplit)
print("\nDe samengevoegde uitvoer van de splitsings-URL:\n",urlUnsplit)
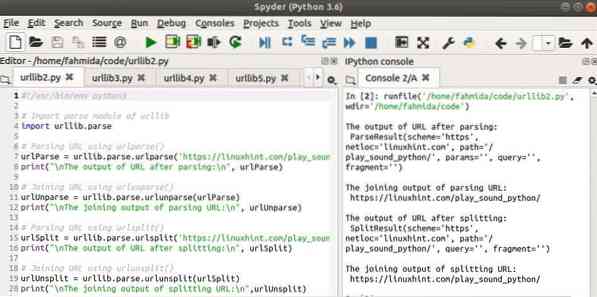
Uitgang:
De volgende vier outputs zullen verschijnen na het uitvoeren van het script:.
Voorbeeld 3: Reactieheader van HTML lezen met urllib.verzoek
Het volgende script laat zien hoe de verschillende delen van de responsheader van de URL kunnen worden opgehaald via de informatie() methode. De urllib.verzoek module die wordt gebruikt om de URL te openen, 'https://linuxhint.com/python_pause_user_input/,' en de header-informatie van deze URL wordt afgedrukt via de informatie() methode. Het volgende deel van dit script laat je zien hoe je elk deel van de kop afzonderlijk kunt lezen. Hier de Server, Datum, en Inhoudstype waarden worden apart afgedrukt.
#!/usr/bin/env python3# Importverzoekmodule van urllib
urllib importeren.verzoek
# Open de URL om te lezen
urlResponse = urllib.verzoek.urlopen('https://linuxhint.com/python_pause_user_input/')
# Uitvoer van antwoordheader van de URL lezen
print(urlReactie).informatie())
# Koptekstinformatie afzonderlijk lezen
print('Responsserver = ', urlResponse.info()["Server"])
print('Reactiedatum is = ', urlResponse.info()["Datum"])
print('Reactie inhoudstype is = ', urlResponse.info()["Inhoudstype"])
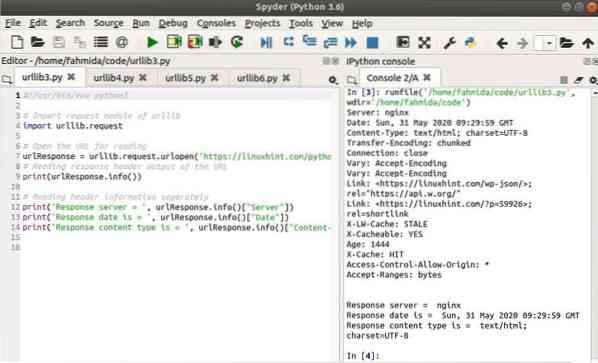
Uitgang:
De volgende uitvoer zal verschijnen na het uitvoeren van het script:.
Voorbeeld 4: URL-antwoorden regel voor regel lezen
In het volgende script wordt een lokaal URL-adres gebruikt:. Hier, een testend HTML-bestand met de naam test.html wordt gemaakt op de locatie, var/www/html. De inhoud van dit bestand wordt regel voor regel gelezen via de voor lus. De strip() methode wordt vervolgens gebruikt om de ruimte aan beide zijden van elke regel te verwijderen. U kunt elk HTML-bestand van de lokale server gebruiken om het script te testen. De inhoud van de test.html bestand dat in dit voorbeeld wordt gebruikt, wordt hieronder weergegeven:.
test.html:
Testpagina
#!/usr/bin/env python3
# URL importeren.aanvraag module
urllib importeren.verzoek
# Open een lokale url om te lezen
response = urllib.verzoek.urlopen('http://localhost/test.html')
# Lees de URL van het antwoord
print ('URL:', reactie.geturl())
# Lees de reactietekst regel voor regel
print("\nInhoud lezen:")
voor lijn in antwoord:
print(regel).strip())
Uitgang:
De volgende uitvoer zal verschijnen na het uitvoeren van het script:.

Voorbeeld 5: Afhandeling van uitzonderingen met urllib.fout.URLFout
Het volgende script laat zien hoe u de URLFout in Python via de urllib.fout module. Elk URL-adres kan als invoer van de gebruiker worden genomen. Als het adres niet bestaat, dan URLFout uitzondering wordt gegenereerd en de reden voor de fout wordt afgedrukt. Als de waarde van de URL een ongeldig formaat heeft, dan is a WaardeFout wordt verhoogd en de aangepaste fout wordt afgedrukt.
#!/usr/bin/env python3# Importeer benodigde modules
urllib importeren.verzoek
urllib importeren.fout
# probeer te blokkeren om een URL te openen om te lezen
proberen:
url = input("Voer een URL-adres in: ")
response = urllib.verzoek.urlopen(url)
print(antwoord).lezen())
# Vang de URL-fout die wordt gegenereerd bij het openen van een URL
behalve urllib.fout.URLError als e:
print("URL-fout:",e.reden)
# Vang de ongeldige URL-fout
behalve ValueError:
print("Vul een geldig URL-adres in")
Uitgang:
Het script wordt drie keer uitgevoerd in de volgende schermafbeelding:. In de eerste iteratie wordt het URL-adres in een ongeldig formaat gegeven, waardoor een ValueError . wordt gegenereerd. Het URL-adres dat in de tweede iteratie wordt gegeven, bestaat niet, waardoor een URLError wordt gegenereerd. Een geldig URL-adres wordt gegeven in de derde iteratie, en dus wordt de inhoud van de URL afgedrukt.

Voorbeeld 6: Afhandeling van uitzonderingen met urllib.fout.HTTP fout
Het volgende script laat zien hoe u de HTTP fout in Python via de urllib.fout module. Een HTML-fout genereert wanneer het opgegeven URL-adres niet bestaat.
#!/usr/bin/env python3# Importeer benodigde modules
urllib importeren.verzoek
urllib importeren.fout
# Voer een geldige URL in
url = input("Voer een URL-adres in: ")
# Verzend verzoek voor de URL
request = urllib.verzoek.Verzoek(url)
proberen:
# Probeer de URL te openen
urllib.verzoek.urlopen(verzoek)
print("URL bestaat")
behalve urllib.fout.HTTPError als e:
# Druk de foutcode en de reden van de fout af
print("Foutcode:%d\nFout reden:%s" %(e.code,e.reden))
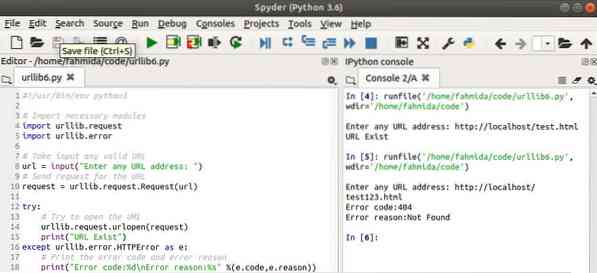
Uitgang:
Hier wordt het script twee keer uitgevoerd. Het eerste URL-adres dat als invoer wordt gebruikt, bestaat en de module heeft een bericht afgedrukt. Het tweede URL-adres dat als invoer wordt gebruikt, bestaat niet en de module heeft de . gegenereerd HTTP fout.
Conclusie
Deze tutorial besprak veel belangrijke toepassingen van de urllib module door verschillende voorbeelden te gebruiken om de lezers te helpen de functies van deze module in Python te leren kennen.


