In dit artikel laat ik je zien hoe je CURL installeert en gebruikt op Ubuntu 18.04 Bionische Bever. Laten we beginnen.
CURL installeren
Werk eerst de pakketrepository-cache van uw Ubuntu-machine bij met de volgende opdracht:
$ sudo apt-get update
De cache van de pakketrepository moet worden bijgewerkt.
CURL is beschikbaar in de officiële pakketrepository van Ubuntu 18.04 Bionische Bever.
U kunt de volgende opdracht uitvoeren om CURL op Ubuntu 18 te installeren:.04:
$ sudo apt-get install curl
CURL moet worden geïnstalleerd.
CURL gebruiken
In dit gedeelte van het artikel laat ik je zien hoe je CURL kunt gebruiken voor verschillende HTTP-gerelateerde taken.
Een URL controleren met CURL
U kunt controleren of een URL geldig is of niet met CURL.
U kunt de volgende opdracht uitvoeren om te controleren of een URL, bijvoorbeeld https://www.google.com is geldig of niet.
$ krul https://www.google.com
Zoals je kunt zien aan de onderstaande schermafbeelding, worden er veel teksten weergegeven op de terminal. Het betekent de URL https://www.google.com is geldig.
Ik heb de volgende opdracht uitgevoerd om je te laten zien hoe een slechte URL eruit ziet.
$ curl http://niet gevonden.niet gevonden
Zoals je kunt zien aan de onderstaande schermafbeelding, staat er Kon host niet oplossen. Het betekent dat de URL niet geldig is.
Een webpagina downloaden met CURL
U kunt een webpagina downloaden van een URL met behulp van CURL.
Het formaat van de opdracht is:
$ curl -o FILENAME URLHier is FILENAME de naam of het pad van het bestand waar u de gedownloade webpagina wilt opslaan. URL is de locatie of het adres van de webpagina.
Stel dat u de officiële webpagina van CURL wilt downloaden en deze wilt opslaan als curl-officieel.html-bestand. Voer de volgende opdracht uit om dat te doen:
$ curl -o curl-officieel.html https://curl.haxx.se/docs/httpscripting.html
De webpagina is gedownload.

Zoals je kunt zien aan de uitvoer van het ls-commando, is de webpagina opgeslagen in curl-officieel.html-bestand.

U kunt het bestand ook openen met een webbrowser, zoals u kunt zien in de onderstaande schermafbeelding.
Een bestand downloaden met CURL
U kunt ook een bestand van internet downloaden met CURL. CURL is een van de beste downloaders voor opdrachtregelbestanden. CURL ondersteunt ook hervatte downloads.
Het formaat van het CURL-commando voor het downloaden van een bestand van internet is:
$ krul -O FILE_URLHier is FILE_URL de link naar het bestand dat u wilt downloaden. De optie -O slaat het bestand op met dezelfde naam als op de externe webserver.
Stel dat u bijvoorbeeld de broncode van de Apache HTTP-server van internet wilt downloaden met CURL. Je zou het volgende commando uitvoeren:
$ curl -O http://www-eu.apache.org/dist//httpd/httpd-2.4.29.teer.gz
Het bestand wordt gedownload.

Het bestand wordt gedownload naar de huidige werkmap.

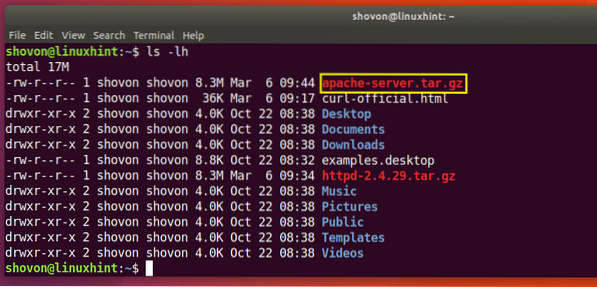
U kunt in het gemarkeerde gedeelte van de uitvoer van de opdracht ls hieronder de http-2 . zien.4.29.teer.gz-bestand dat ik zojuist heb gedownload.

Als u het bestand met een andere naam dan die op de externe webserver wilt opslaan, voert u de opdracht als volgt uit:.
$ curl -o apache-server.teer.gz http://www-eu.apache.org/dist//httpd/httpd-2.4.29.teer.gz
Het downloaden is voltooid.

Zoals je kunt zien in het gemarkeerde gedeelte van de uitvoer van de opdracht ls hieronder, wordt het bestand onder een andere naam opgeslagen.
Downloads hervatten met CURL
U kunt ook mislukte downloads hervatten met CURL. Dit is wat CURL tot een van de beste opdrachtregeldownloaders maakt.
Als je de -O optie hebt gebruikt om een bestand met CURL te downloaden en het is mislukt, voer je de volgende opdracht uit om het opnieuw te hervatten:.
$ curl -C - -O YOUR_DOWNLOAD_LINKHier is YOUR_DOWNLOAD_LINK de URL van het bestand dat je probeerde te downloaden met CURL maar dat is mislukt.
Stel dat u het bronarchief van Apache HTTP Server probeerde te downloaden en dat uw netwerk halverwege werd verbroken en dat u de download opnieuw wilt hervatten.
Voer de volgende opdracht uit om het downloaden met CURL te hervatten:
$ krul -C - -O http://www-eu.apache.org/dist//httpd/httpd-2.4.29.teer.gz
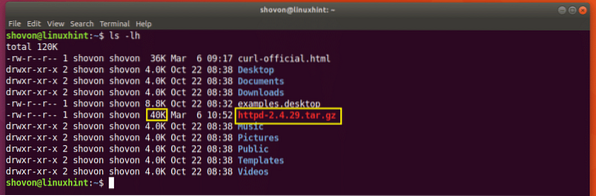
Het downloaden wordt hervat.

Als u het bestand hebt opgeslagen met een andere naam dan die op de externe webserver staat, moet u de opdracht als volgt uitvoeren:
$ curl -C - -o FILENAME DOWNLOAD_LINKHier is FILENAME de naam van het bestand dat je hebt gedefinieerd voor de download. Onthoud dat de BESTANDSNAAM moet overeenkomen met de bestandsnaam waarmee u de download probeerde op te slaan zoals toen de download mislukt.
Beperk de downloadsnelheid met CURL
Mogelijk hebt u een enkele internetverbinding die is verbonden met de wifi-router die iedereen in uw gezin of kantoor gebruikt. Als u een groot bestand met CURL downloadt, kunnen andere leden van hetzelfde netwerk problemen ondervinden wanneer ze internet proberen te gebruiken.
Je kunt de downloadsnelheid beperken met CURL als je wilt.
Het formaat van de opdracht is:
$ curl --limit-rate DOWNLOAD_SPEED -O DOWNLOAD_LINKHier is DOWNLOAD_SPEED de snelheid waarmee u het bestand wilt downloaden.
Laten we zeggen dat je de downloadsnelheid 10 KB wilt hebben, voer de volgende opdracht uit om dat te doen:
$ curl --limit-rate 10K -O http://www-eu.apache.org/dist//httpd/httpd-2.4.29.teer.gz
Zoals u kunt zien, wordt de snelheid beperkt tot 10 Kilo Bytes (KB) wat gelijk is aan bijna 10000 bytes (B).

HTTP-headerinformatie verkrijgen met CURL
Wanneer u met REST API's werkt of websites ontwikkelt, moet u mogelijk de HTTP-headers van een bepaalde URL controleren om er zeker van te zijn dat uw API of website de gewenste HTTP-headers verzendt. Dat kan met CURL.
U kunt de volgende opdracht uitvoeren om de header-informatie van https://www . te krijgen.google.com:
$ krul -I https://www.google.com
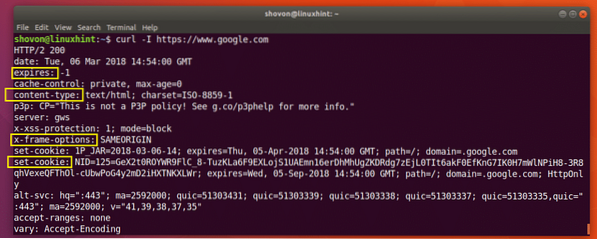
Zoals je kunt zien aan de onderstaande schermafbeelding, zijn alle HTTP-responsheaders van https://www.google.com wordt vermeld.
Zo installeer en gebruik je CURL op Ubuntu 18.04 Bionische Bever. Bedankt voor het lezen van dit artikel.


