In deze les over Machine Learning met scikit-learn leren we verschillende aspecten van dit uitstekende Python-pakket waarmee we eenvoudige en complexe Machine Learning-mogelijkheden kunnen toepassen op een diverse reeks gegevens, samen met functionaliteiten om de hypothese die we stellen te testen.
Het scikit-learn-pakket bevat eenvoudige en efficiënte tools om datamining en data-analyse op datasets toe te passen en deze algoritmen zijn beschikbaar om in verschillende contexten toe te passen. Het is een open-sourcepakket dat beschikbaar is onder een BSD-licentie, wat betekent dat we deze bibliotheek zelfs commercieel kunnen gebruiken. Het is gebouwd bovenop matplotlib, NumPy en SciPy, dus het is veelzijdig van aard. We zullen Anaconda met Jupyter-notebook gebruiken om voorbeelden in deze les te presenteren.
Wat scikit-learn biedt?
De scikit-learn bibliotheek richt zich volledig op datamodellering. Houd er rekening mee dat er geen grote functionaliteiten aanwezig zijn in de scikit-learn als het gaat om het laden, manipuleren en samenvatten van gegevens. Hier zijn enkele van de populaire modellen die scikit-learn ons biedt:
- Clustering om gelabelde gegevens te groeperen
- Gegevenssets om testdatasets te leveren en modelgedrag te onderzoeken
- Kruisvalidatie om de prestaties van gesuperviseerde modellen op ongeziene gegevens te schatten
- Ensemble methoden om de voorspellingen van meerdere gesuperviseerde modellen te combineren
- Functie-extractie om attributen te definiëren in afbeeldings- en tekstgegevens
Installeer Python scikit-learn
Even een opmerking voordat we het installatieproces starten, we gebruiken een virtuele omgeving voor deze les die we hebben gemaakt met het volgende commando:
python -m virtualenv scikitbron scikit/bin/activeren
Zodra de virtuele omgeving actief is, kunnen we de panda-bibliotheek in de virtuele omgeving installeren, zodat voorbeelden die we vervolgens maken, kunnen worden uitgevoerd:
pip install scikit-learnOf we kunnen Conda gebruiken om dit pakket te installeren met de volgende opdracht:
conda installeer scikit-learnWe zien zoiets als dit wanneer we het bovenstaande commando uitvoeren:

Zodra de installatie is voltooid met Conda, kunnen we het pakket in onze Python-scripts gebruiken als:
importeer sklearnLaten we scikit-learn gaan gebruiken in onze scripts om geweldige Machine Learning-algoritmen te ontwikkelen.
Gegevenssets importeren
Een van de leuke dingen van scikit-learn is dat het vooraf is geladen met voorbeeldgegevenssets waarmee het gemakkelijk is om snel aan de slag te gaan. De datasets zijn de iris en cijfers datasets voor classificatie en de huizenprijzen boston dataset voor regressietechnieken. In deze sectie zullen we bekijken hoe we de iris-gegevensset kunnen laden en gebruiken.
Om een dataset te importeren, moeten we eerst de juiste module importeren en vervolgens de dataset in het bezit krijgen:
van sklearn datasets importereniris = gegevenssets.load_iris()
cijfers = datasets.load_digits()
cijfers.gegevens
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:

Alle uitvoer is verwijderd voor de beknoptheid. Dit is de dataset die we in deze les voornamelijk zullen gebruiken, maar de meeste concepten kunnen worden toegepast op over het algemeen alle datasets.
Gewoon een leuk weetje om te weten dat er meerdere modules aanwezig zijn in de scikit ecosysteem, waarvan er één is: leren gebruikt voor Machine Learning-algoritmen. Zie deze pagina voor vele andere aanwezige modules.
De dataset verkennen
Nu we de verstrekte cijfers-dataset in ons script hebben geïmporteerd, moeten we beginnen met het verzamelen van basisinformatie over de dataset en dat is wat we hier zullen doen. Hier zijn de basisdingen die u moet onderzoeken terwijl u informatie over een dataset zoekt:
- De doelwaarden of labels
- Het beschrijvingskenmerk
- De sleutels die beschikbaar zijn in de gegeven dataset
Laten we een kort codefragment schrijven om de bovenstaande drie informatie uit onze dataset te extraheren:
print('Doel: ', cijfers.doelwit)print('Sleutels: ', cijfers.sleutels())
print('Beschrijving: ', cijfers.BESCHRIJVING)
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
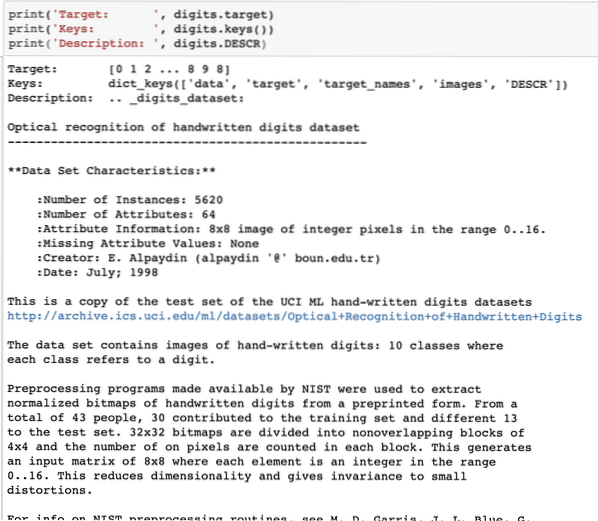
Houd er rekening mee dat de variabele cijfers niet eenvoudig zijn. Toen we de dataset met cijfers uitprinten, bevatte deze eigenlijk numpy arrays. We zullen zien hoe we toegang kunnen krijgen tot deze arrays. Let hiervoor op de sleutels die beschikbaar zijn in de cijfers die we in het laatste codefragment hebben afgedrukt.
We beginnen met het verkrijgen van de vorm van de arraygegevens, de rijen en kolommen die de array heeft. Hiervoor moeten we eerst de feitelijke gegevens krijgen en vervolgens de vorm krijgen:
cijfers_set = cijfers.gegevensprint(digits_set.vorm)
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:

Dit betekent dat we 1797 voorbeelden in onze dataset hebben, samen met 64 gegevenskenmerken (of kolommen). We hebben ook enkele doellabels die we hier zullen visualiseren met behulp van matplotlib. Hier is een codefragment dat ons hierbij helpt:
matplotlib importeren.pyplot als plt# Voeg de afbeeldingen en doellabels samen als een lijst
images_and_labels = lijst(zip(cijfers .).afbeeldingen, cijfers.doelwit))
voor index, (afbeelding, label) in enumerate(images_and_labels[:8]):
# initialiseer een subplot van 2X4 op de i+1-de positie
plt.subplot(2, 4, index + 1)
# U hoeft geen assen te plotten
plt.as('uit')
# Toon afbeeldingen in alle subplots
plt.imshow(afbeelding, cmap=plt.cm.grey_r,interpolation='dichtstbijzijnde')
# Voeg een titel toe aan elke subplot
plt.title('Training: ' + str(label))
plt.tonen()
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:

Merk op hoe we de twee NumPy-arrays aan elkaar hebben gezipt voordat ze op een 4 bij 2 raster werden geplot zonder enige asseninformatie. Nu zijn we zeker van de informatie die we hebben over de dataset waarmee we werken.
Nu we weten dat we 64 gegevensfuncties hebben (wat overigens veel functies zijn), is het een uitdaging om de werkelijke gegevens te visualiseren. We hebben hier echter een oplossing voor.
Hoofdcomponentenanalyse (PCA)
Dit is geen tutorial over PCA, maar laten we een klein idee geven van wat het is. Omdat we weten dat we twee technieken hebben om het aantal kenmerken van een dataset te verminderen:
- Functie eliminatie
- Functie-extractie
Terwijl de eerste techniek het probleem van verloren gegevenskenmerken onder ogen ziet, zelfs als ze belangrijk zouden kunnen zijn, heeft de tweede techniek geen last van het probleem, omdat we met behulp van PCA nieuwe gegevenskenmerken construeren (minder in aantal) waarbij we de variabelen op zo'n manier invoeren dat we de "minst belangrijke" variabelen kunnen weglaten, terwijl we toch de meest waardevolle delen van alle variabelen behouden.
Als verwacht, PCA helpt ons de hoge dimensionaliteit van gegevens te verminderen wat een direct resultaat is van het beschrijven van een object met behulp van veel gegevensfuncties. Niet alleen cijfers, maar veel andere praktische datasets hebben een groot aantal functies, waaronder gegevens van financiële instellingen, weer- en economiegegevens voor een regio, enz. Wanneer we PCA uitvoeren op de cijfers-dataset, ons doel is om slechts 2 functies te vinden zodat ze de meeste kenmerken hebben van de dataset.
Laten we een eenvoudig codefragment schrijven om PCA toe te passen op de dataset met cijfers om ons lineaire model van slechts 2 functies te krijgen:
van sklearn.ontleding import PCAfeature_pca = PCA(n_componenten=2)
verminderde_data_random = feature_pca.fit_transform(cijfers.gegevens)
model_pca = PCA(n_componenten=2)
verminderde_data_pca = model_pca.fit_transform(cijfers.gegevens)
verminderde_data_pca.vorm
print(reduced_data_willekeurig)
print(reduced_data_pca)
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
[[ -1.2594655 21.27488324][ 7.95762224 -20.76873116]
[ 6.99192123 -9.95598191]
…
[ 10.8012644 -6.96019661]
[ -4.87210598 12.42397516]
[ -0.34441647 6.36562581]]
[[ -1.25946526 21.27487934]
[ 7.95761543 -20.76870705]
[ 6.99191947 -9.9559785 ]
…
[ 10.80128422 -6.96025542]
[ -4.87210144 12.42396098]
[ -0.3443928 6.36555416]]
In de bovenstaande code vermelden we dat we slechts 2 functies nodig hebben voor de dataset.
Nu we een goede kennis hebben van onze dataset, kunnen we beslissen wat voor soort machine learning-algoritmen we erop kunnen toepassen. Het kennen van een dataset is belangrijk omdat we zo kunnen beslissen welke informatie eruit gehaald kan worden en met welke algoritmen. Het helpt ons ook om de hypothese die we stellen te testen terwijl we toekomstige waarden voorspellen.
K-betekent clustering toepassen
Het k-means clusteringalgoritme is een van de gemakkelijkste clusteringalgoritmen voor leren zonder toezicht. In deze clustering hebben we een willekeurig aantal clusters en we classificeren onze datapunten in een van deze clusters. Het k-means-algoritme vindt het dichtstbijzijnde cluster voor elk van de gegeven gegevenspunten en wijst dat gegevenspunt toe aan dat cluster.
Zodra de clustering is voltooid, wordt het centrum van het cluster opnieuw berekend, de datapunten krijgen nieuwe clusters toegewezen als er wijzigingen zijn. Dit proces wordt herhaald totdat de datapunten stoppen met het veranderen van hun clusters om stabiliteit te bereiken.
Laten we dit algoritme gewoon toepassen zonder enige voorbewerking van de gegevens. Voor deze strategie is het codefragment vrij eenvoudig:
van sklearn importclusterk = 3
k_means = cluster.KBetekent(k)
# gegevens aanpassen
k_betekent.passen (cijfers).gegevens)
# afdrukresultaten
print(k_means.labels_[::10])
print(cijfers).doel[::10])
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
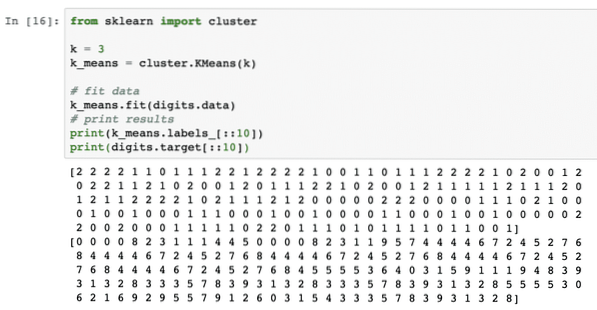
In de bovenstaande uitvoer kunnen we zien dat verschillende clusters aan elk van de gegevenspunten worden verstrekt.
Conclusie
In deze les hebben we gekeken naar een uitstekende machine learning-bibliotheek, scikit-learn. We hebben geleerd dat er veel andere modules beschikbaar zijn in de scikit-familie en we hebben een eenvoudig k-means-algoritme toegepast op de verstrekte dataset. Er zijn veel meer algoritmen die op de dataset kunnen worden toegepast, afgezien van k-means clustering die we in deze les hebben toegepast, we moedigen u aan dit te doen en uw resultaten te delen.
Deel uw feedback over de les op Twitter met @sbmaggarwal en @LinuxHint.


