TextBlob gebruiken in de industrie
Zoals het klinkt, is TextBlob een Python-pakket om eenvoudige en complexe tekstanalysebewerkingen uit te voeren op tekstuele gegevens zoals spraaktagging, extractie van zelfstandige naamwoorden, sentimentanalyse, classificatie, vertaling en meer. Hoewel er veel meer use-cases zijn voor TextBlob die we in andere blogs zouden kunnen behandelen, behandelt deze het analyseren van Tweets op hun sentimenten.
Analysesentimenten hebben een groot praktisch nut voor een groot aantal scenario's:
- Tijdens politieke verkiezingen in een geografische regio kunnen tweets en andere activiteiten op sociale media worden gevolgd om geschatte exitpolls en resultaten over de aanstaande regering te produceren
- Verschillende bedrijven kunnen tekstanalyse op sociale media gebruiken om snel eventuele negatieve gedachten te identificeren die via sociale media in een bepaalde regio circuleren om de problemen te identificeren en op te lossen
- Sommige producten gebruiken zelfs tweets om de medische neigingen van mensen op basis van hun sociale activiteiten in te schatten, zoals het soort tweets dat ze maken, misschien gedragen ze zich suïcidaal, enz.
Aan de slag met TextBlob
We weten dat je hier kwam om wat praktische code te zien met betrekking tot een sentimentele analysator met TextBlob. Daarom zullen we deze sectie extreem kort houden voor het introduceren van TextBlob voor nieuwe lezers. Een opmerking voordat u begint, is dat we a . gebruiken virtuele omgeving voor deze les die we hebben gemaakt met het volgende commando
python -m virtualenv textblobbron tekstblob/bin/activeren
Zodra de virtuele omgeving actief is, kunnen we de TextBlob-bibliotheek in de virtuele omgeving installeren, zodat de voorbeelden die we vervolgens maken, kunnen worden uitgevoerd:
pip install -U textblobZodra u de bovenstaande opdracht uitvoert, is dat het niet meer. TextBlob heeft ook toegang nodig tot enkele trainingsgegevens die kunnen worden gedownload met de volgende opdracht:
python -m tekstblob.download_corporaU ziet zoiets als dit door de benodigde gegevens te downloaden:
Je kunt ook Anaconda gebruiken om deze voorbeelden uit te voeren, wat gemakkelijker is. Als je het op je computer wilt installeren, kijk dan naar de les die beschrijft "Hoe Anaconda Python op Ubuntu 18 te installeren".04 LTS” en deel uw feedback.
Om een heel snel voorbeeld voor TextBlob te laten zien, is hier een voorbeeld rechtstreeks uit de documentatie:
van textblob import TextBlobtekst = "'
De titulaire dreiging van The Blob heeft me altijd de ultieme film gevonden
monster: een onverzadigbaar hongerige, amoebe-achtige massa die kan doordringen
vrijwel elke beveiliging, in staat - als een gedoemde dokter huiveringwekkend -
beschrijft het -- "vlees assimileren bij contact".
Snide vergelijkingen met gelatine zijn verdoemd, het is een concept met de meeste
verwoestende van mogelijke gevolgen, niet anders dan het grijze goo-scenario
voorgesteld door technologische theoretici die bang zijn voor
kunstmatige intelligentie tiert welig.
"'
blob = TekstBlob(tekst)
print(blob).labels)
print(blob).zelfstandige naamwoorden)
voor zin in blob.zinnen:
print(zin).sentiment.polariteit)
klodder.vertalen(naar="es")
Wanneer we het bovenstaande programma uitvoeren, krijgen we de volgende tagwoorden en tot slot de emoties die de twee zinnen in de voorbeeldtekst laten zien:
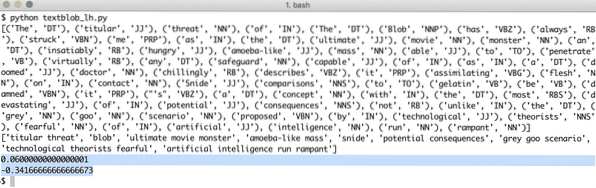
Tagwoorden en emoties helpen ons de belangrijkste woorden te identificeren die daadwerkelijk een effect hebben op de sentimentberekening en de polariteit van de zin die aan de. Dit komt omdat de betekenis en het sentiment van de woorden veranderen in de volgorde waarin ze worden gebruikt, dus dit moet allemaal dynamisch worden gehouden.
Op lexicon gebaseerde sentimentanalyse
Elk sentiment kan eenvoudig worden gedefinieerd als een functie van semantische oriëntatie en intensiteit van woorden die in een zin worden gebruikt. Met een op lexicon gebaseerde benadering voor het identificeren van emoties in een bepaald woord of zin, wordt elk woord geassocieerd met een score die de emotie beschrijft die het woord vertoont (of op zijn minst probeert te vertonen). Meestal hebben de meeste woorden een vooraf gedefinieerd woordenboek over hun lexicale score, maar als het op mensen aankomt, is er altijd sarcasme bedoeld, dus die woordenboeken zijn niet iets waar we 100% op kunnen vertrouwen. De WordStat Sentiment Dictionary bevat meer dan 9164 negatieve en 4847 positieve woordpatronen.
Ten slotte is er een andere methode om sentimentanalyse uit te voeren (buiten het bestek van deze les), namelijk een Machine Learning-techniek, maar we kunnen niet alle woorden in een ML-algoritme gebruiken, omdat we zeker problemen zullen krijgen met overfitting. We kunnen een van de functieselectie-algoritmen zoals Chi Square of Mutual Information toepassen voordat we het algoritme trainen. We zullen de bespreking van de ML-benadering beperken tot alleen deze tekst.
Twitter-API gebruiken
Ga hier naar de startpagina van de app-ontwikkelaar om tweets rechtstreeks van Twitter te ontvangen:
https://ontwikkelaar.twitteren.com/nl/apps
Registreer uw aanvraag door het formulier als volgt in te vullen:
Zodra u alle token beschikbaar heeft op het tabblad "Sleutels en tokens":
We kunnen de sleutels gebruiken om de vereiste tweets van Twitter API te krijgen, maar we moeten nog een Python-pakket installeren dat het zware werk voor ons doet bij het verkrijgen van de Twitter-gegevens:
pip installeer tweepyHet bovenstaande pakket wordt gebruikt voor het voltooien van alle zware communicatie met de Twitter API. Het voordeel voor Tweepy is dat we niet veel code hoeven te schrijven wanneer we onze applicatie willen authenticeren voor interactie met Twitter-gegevens en het wordt automatisch verpakt in een zeer eenvoudige API die wordt weergegeven via het Tweepy-pakket. Bovenstaand pakket kunnen we in ons programma importeren als:
import tweepyHierna hoeven we alleen de juiste variabelen te definiëren waar we de Twitter-sleutels kunnen bewaren die we van de ontwikkelaarsconsole hebben ontvangen:
consumer_key = '[consumer_key]'consumer_key_secret = '[consumer_key_secret]'
access_token = '[access_token]'
access_token_secret = '[access_token_secret]'
Nu we geheimen voor Twitter in de code hebben gedefinieerd, zijn we eindelijk klaar om een verbinding met Twitter tot stand te brengen om de Tweets te ontvangen en te beoordelen, ik bedoel, ze te analyseren. Natuurlijk moet de verbinding met Twitter tot stand worden gebracht met behulp van de OAuth-standaard en Het Tweepy-pakket is handig om de verbinding tot stand te brengen ook:
twitter_auth = tweepy.OAuthHandler(consumer_key, consumer_key_secret)Ten slotte hebben we de verbinding nodig:
api = tweepy.API(twitter_auth)Met behulp van de API-instantie kunnen we Twitter zoeken naar elk onderwerp dat we eraan doorgeven. Het kan een enkel woord zijn of meerdere woorden. Ook al raden we aan om voor de precisie zo min mogelijk woorden te gebruiken. Laten we hier een voorbeeld proberen:
pm_tweets = api.zoeken("India")De bovenstaande zoekopdracht geeft ons veel Tweets, maar we zullen het aantal tweets dat we terugkrijgen beperken, zodat de oproep niet te veel tijd kost, omdat deze later ook door het TextBlob-pakket moet worden verwerkt:
pm_tweets = api.zoeken("India", count=10)Ten slotte kunnen we de tekst van elke Tweet en het bijbehorende sentiment afdrukken:
voor tweet in pm_tweets:print(tweet).tekst)
analyse = TextBlob(tweet.tekst)
print(analyse).sentiment)
Zodra we het bovenstaande script hebben uitgevoerd, krijgen we de laatste 10 vermeldingen van de genoemde zoekopdracht en wordt elke tweet geanalyseerd op sentimentwaarde. Hier is de uitvoer die we hiervoor hebben ontvangen:

Merk op dat je ook een streaming-sentimentanalyse-bot kunt maken met TextBlob en Tweepy. Met Tweepy kan een websocket-streamingverbinding tot stand worden gebracht met de Twitter API en kunnen Twitter-gegevens in realtime worden gestreamd.
Conclusie
In deze les hebben we gekeken naar een uitstekend tekstanalysepakket waarmee we tekstuele sentimenten kunnen analyseren en nog veel meer. TextBlob is populair vanwege de manier waarop we eenvoudig met tekstuele gegevens kunnen werken zonder ingewikkelde API-aanroepen. We hebben ook Tweepy geïntegreerd om gebruik te maken van Twitter-gegevens. We kunnen het gebruik eenvoudig aanpassen aan een streaming-use-case met hetzelfde pakket en heel weinig wijzigingen in de code zelf.
Deel alstublieft uw feedback over de les op Twitter met @linuxhint en @sbmaggarwal (dat ben ik!).


