Wat is Apache Solr
Apache Solr is een van de meest populaire NoSQL-databases die kan worden gebruikt om gegevens op te slaan en in bijna realtime op te vragen. Het is gebaseerd op Apache Lucene en is geschreven in Java. Net als Elasticsearch ondersteunt het databasequery's via REST API's. Dit betekent dat we eenvoudige HTTP-aanroepen kunnen gebruiken en HTTP-methoden kunnen gebruiken zoals GET, POST, PUT, DELETE enz. om toegang te krijgen tot gegevens. Het biedt ook een optie om gegevens in de vorm van XML of JSON te krijgen via de REST API's.
Architectuur: Apache Solr
Voordat we met Apache Solr kunnen gaan werken, moeten we de componenten begrijpen waaruit Apache Solr bestaat. Laten we eens kijken naar enkele componenten die het heeft:
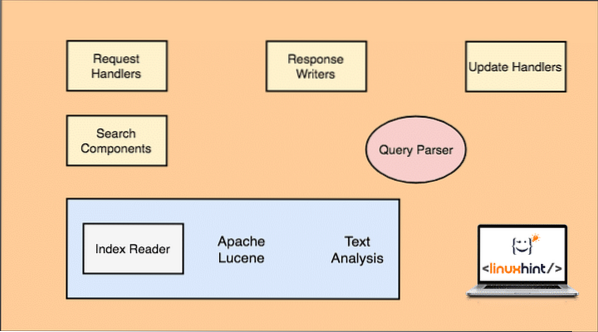
Apache Solr-architectuur
Merk op dat alleen de belangrijkste componenten voor Solr in bovenstaande afbeelding worden getoond:. Laten we ook hier hun functionaliteit begrijpen:
- Verzoekafhandelaars: De verzoeken die een klant doet aan Solr worden beheerd door een Request Handler. Het verzoek kan van alles zijn, van het toevoegen van een nieuw record tot het bijwerken van een index in Solr. Handlers identificeren het type verzoek van de HTTP-methode die wordt gebruikt met de verzoektoewijzing.
- Zoekcomponent: Dit is een van de belangrijkste componenten waar Solr om bekend staat. Search Component zorgt voor het uitvoeren van zoekgerelateerde bewerkingen zoals vaagheid, spellingcontrole, zoekopdrachten op termen, enz.
- Query-parser: dit is de component die de query die een client doorgeeft aan de verzoekbehandelaar daadwerkelijk parseert en een query opsplitst in meerdere delen die kunnen worden begrepen door de onderliggende engine
- Reactie Schrijver: Dit onderdeel is verantwoordelijk voor het beheer van het uitvoerformaat voor de query's die aan de engine worden doorgegeven. Met Response Writer kunnen we een uitvoer leveren in verschillende formaten zoals XML, JSON enz.
- Analysator/Tokenizer: Lucene Engine begrijpt zoekopdrachten in de vorm van meerdere tokens. Solr analyseert de query, verdeelt deze in meerdere tokens en geeft deze door aan de Lucene Engine.
- Verwerkingsverzoekverwerker: Wanneer een query wordt uitgevoerd en deze bewerkingen uitvoert zoals het bijwerken van een index en de gegevens die ermee verband houden, is de component Update Request Processor verantwoordelijk voor het beheren van de gegevens in de index en het wijzigen ervan.
Aan de slag met Apache Solr
Om Apache Solr te gaan gebruiken, moet het op de machine zijn geïnstalleerd. Lees hiervoor Installeer Apache Solr op Ubuntu.
Zorg ervoor dat je een actieve Solr-installatie hebt als je voorbeelden wilt proberen die we later in de les presenteren en de beheerderspagina is bereikbaar op localhost:
Apache Solr-startpagina
Gegevens invoegen
Laten we om te beginnen eens kijken naar een verzameling in Solr die we noemen als linux_hint_collection. Het is niet nodig om deze verzameling expliciet te definiëren, want wanneer we het eerste object invoegen, wordt de verzameling automatisch gemaakt. Laten we onze eerste REST API-aanroep proberen om een nieuw object in te voegen in de verzameling met de naam linux_hint_collection.
Gegevens invoegen
curl -X POST -H 'Inhoudstype: applicatie/json''http://localhost:8983/solr/linux_hint_collection/update/json/docs' --data-binary '
"id": "iduye",
"naam": "Shubham"
'
Dit is wat we terugkrijgen met deze opdracht:

Commando om gegevens in Solr . in te voegen
Gegevens kunnen ook worden ingevoegd met behulp van de Solr-startpagina die we eerder hebben bekeken. Laten we dit hier proberen, zodat alles duidelijk is:
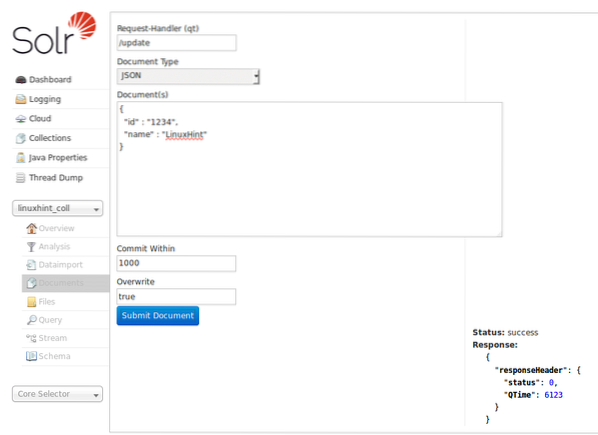
Gegevens invoegen via Solr Homepage
Aangezien Solr een uitstekende manier van interactie heeft met HTTP RESTful API's, zullen we vanaf nu DB-interactie demonstreren met dezelfde API's en zullen we ons niet veel concentreren op het invoegen van gegevens via de Solr-webpagina.
Alle collecties weergeven
We kunnen ook alle collecties in Apache Solr weergeven met behulp van een REST API. Hier is de opdracht die we kunnen gebruiken:
Alle collecties weergeven
curl http://localhost:8983/solr/admin/collections?acties=LIJST&wt=jsonLaten we de uitvoer voor deze opdracht bekijken:
We zien hier twee collecties die bestaan in onze Solr-installatie.
Object op ID ophalen
Laten we nu eens kijken hoe we gegevens uit de Solr-verzameling kunnen KRIJGEN met een specifieke ID. Hier is de REST API-opdracht:
Object op ID ophalen
curl http://localhost:8983/solr/linux_hint_collection/get?id=iduyeDit is wat we terugkrijgen met deze opdracht:
Alle gegevens ophalen
In onze laatste REST API hebben we gegevens opgevraagd met een specifieke ID. Deze keer krijgen we alle gegevens in onze Solr-collectie.
Object op ID ophalen
curl http://localhost:8983/solr/linux_hint_collection/select?q=*:*Dit is wat we terugkrijgen met deze opdracht: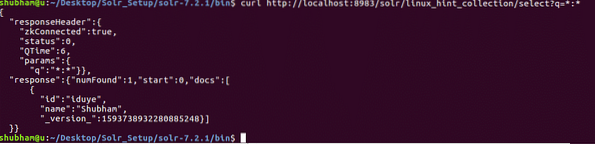
Merk op dat we '*:*' hebben gebruikt in de queryparameter. Dit geeft aan dat Solr alle gegevens in de verzameling moet retourneren. Zelfs als we hebben gespecificeerd dat alle gegevens moeten worden geretourneerd, begrijpt Solr dat de verzameling een grote hoeveelheid gegevens kan bevatten en dus, het zal alleen de eerste 10 documenten retourneren.
Alle gegevens verwijderen
Tot nu toe gebruikten alle API's die we probeerden een JSON-indeling. Deze keer proberen we het XML-queryformaat. Het gebruik van XML-indeling lijkt sterk op JSON, omdat XML ook zelfbeschrijvend is.
Laten we een commando proberen om alle gegevens die we in onze collectie hebben te verwijderen.
Alle gegevens verwijderen
curl "http://localhost:8983/solr/linux_hint_collection/update?commit=true" -H "Inhoudstype: tekst/xml" --data-binary "*:*"Dit is wat we terugkrijgen met deze opdracht:

Alle gegevens verwijderen met XML-query
Als we nu opnieuw proberen alle gegevens te krijgen, zullen we zien dat er nu geen gegevens beschikbaar zijn:

Alle gegevens ophalen
Totaal aantal objecten
Laten we voor een laatste CURL-commando een commando bekijken waarmee we het aantal objecten kunnen vinden dat aanwezig is in een index. Hier is de opdracht voor hetzelfde:
Totaal aantal objecten
curl http://localhost:8983/solr/linux_hint_collection/query?debug=query&q=*:*Dit is wat we terugkrijgen met deze opdracht:
Tel het aantal objecten
Conclusie
In deze les hebben we gekeken hoe we Apache Solr kunnen gebruiken en query's kunnen doorgeven met curl in zowel JSON- als XML-indeling. We hebben ook gezien dat het Solr-beheerpaneel op dezelfde manier nuttig is als alle curl-opdrachten die we hebben bestudeerd.


