Als we het hebben over gedistribueerde systemen zoals hierboven, komen we het probleem van analyse en monitoring tegen. Elk knooppunt genereert veel informatie over zijn eigen gezondheid (CPU-gebruik, geheugen, enz.) en over de applicatiestatus, samen met wat de gebruikers proberen te doen. Deze gegevens moeten worden vastgelegd in:
- Dezelfde volgorde waarin ze zijn gemaakt,
- Gescheiden in termen van urgentie (realtime analyses of batches met gegevens), en vooral:,
- Het mechanisme waarmee ze worden verzameld, moet zelf gedistribueerd en schaalbaar zijn, anders blijven we achter met een enkel storingspunt. Iets wat het ontwerp van het gedistribueerde systeem moest vermijden.
Waarom Kafka . gebruiken?
Apache Kafka wordt gepitcht als een gedistribueerd streamingplatform. In Kafka-jargon, Producenten continu gegevens genereren (stromen) en Consumenten zijn verantwoordelijk voor de verwerking, opslag en analyse ervan. Kafka Makelaars zijn verantwoordelijk om ervoor te zorgen dat in een gedistribueerd scenario de gegevens zonder enige inconsistentie van producenten tot consumenten kunnen reiken. Een set Kafka-makelaars en een ander stukje software genaamd dierentuinmedewerker een typische Kafka-implementatie vormen.
De gegevensstroom van veel producenten moet worden geaggregeerd, gepartitioneerd en naar meerdere consumenten worden verzonden, er komt veel schuifwerk bij kijken. Het vermijden van inconsistentie is geen gemakkelijke taak. Dit is waarom we Kafka . nodig hebben.
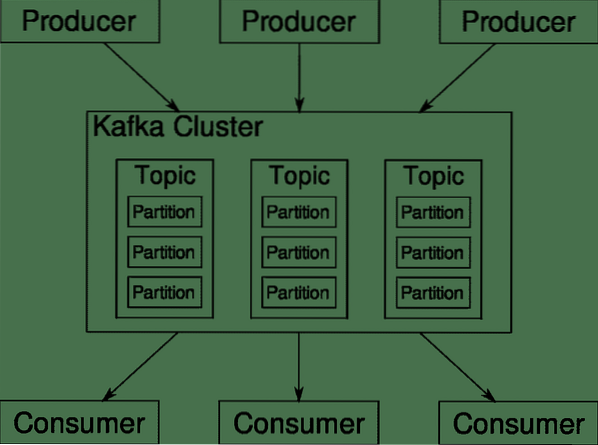
De scenario's waarin Kafka kan worden gebruikt, zijn behoorlijk divers. Alles, van IOT-apparaten tot clusters van VM's tot uw eigen bare-metal servers op locatie. Overal waar veel 'dingen' tegelijk je aandacht willen.. .Dat is niet erg wetenschappelijk, toch?? Welnu, de Kafka-architectuur is een konijnenhol op zich en verdient een onafhankelijke behandeling. Laten we eerst een zeer oppervlakkige implementatie van de software bekijken.
Docker Compose gebruiken
Op welke fantasierijke manier u ook besluit Kafka te gebruiken, één ding is zeker: u zult het niet als een enkele instantie gebruiken. Het is niet bedoeld om op die manier te worden gebruikt, en zelfs als je gedistribueerde app voorlopig maar één instantie (broker) nodig heeft, zal het uiteindelijk groeien en moet je ervoor zorgen dat Kafka het kan bijhouden.
Docker-compose is de perfecte partner voor dit soort schaalbaarheid. Voor het uitvoeren van Kafka-brokers op verschillende VM's, containeriseren we het en gebruiken we Docker Compose om de implementatie en schaling te automatiseren. Docker-containers zijn zeer schaalbaar op zowel enkele Docker-hosts als in een cluster als we Docker Swarm of Kubernetes gebruiken. Het is dus logisch om het te gebruiken om Kafka schaalbaar te maken.
Laten we beginnen met een enkele brokerinstantie. Maak een map met de naam apache-kafka en maak daarin je docker-compose.yml.
$ mkdir apache-kafka$ cd apache-kafka
$ vim docker-compose.yml
De volgende inhoud wordt in uw docker-compose geplaatst:.yml-bestand:
versie: '3'Diensten:
dierentuinmedewerker:
afbeelding: wurstmeister/dierenverzorger
kafka:
afbeelding: wurstmeister/kafka
poorten:
- "9092:9092"
milieu:
KAFKA_ADVERTISED_HOST_NAME: localhost
KAFKA_ZOOKEEPER_CONNECT: dierenverzorger:2181
Nadat u de bovenstaande inhoud in uw opstelbestand hebt opgeslagen, voert u vanuit dezelfde map het volgende uit:
$ docker-compose up -dOké, dus wat hebben we hier gedaan??
De Docker-Compose begrijpen.yml
Compose start twee services zoals vermeld in het yml-bestand. Laten we eens goed naar het bestand kijken. De eerste afbeelding is een dierenverzorger die Kafka nodig heeft om verschillende makelaars, de netwerktopologie bij te houden en andere informatie te synchroniseren. Aangezien zowel zookeeper- als kafka-services deel gaan uitmaken van hetzelfde bridge-netwerk (dit wordt gemaakt wanneer we docker-compose up uitvoeren), hoeven we geen poorten vrij te geven. Kafka-makelaar kan praten met dierenverzorger en dat is alles wat de dierenverzorger nodig heeft.
De tweede service is Kafka zelf en we voeren er slechts één exemplaar van uit, dat wil zeggen één makelaar. Idealiter zou u meerdere brokers willen gebruiken om de gedistribueerde architectuur van Kafka . te benutten. De service luistert op poort 9092 die is toegewezen aan hetzelfde poortnummer op de Docker Host en zo communiceert de service met de buitenwereld.
De tweede service heeft ook een aantal omgevingsvariabelen. Ten eerste is KAFKA_ADVERTISED_HOST_NAME ingesteld op localhost. Dit is het adres waar Kafka draait, en waar producenten en consumenten het kunnen vinden. Nogmaals, dit zou moeten zijn ingesteld op localhost, maar eerder op het IP-adres of de hostnaam hiermee kunnen de servers in uw netwerk worden bereikt. Ten tweede is de hostnaam en het poortnummer van uw dierenverzorgerservice. Omdat we de dierenverzorgersservice hebben genoemd ... nou ja, dierenverzorger, dat is wat de hostnaam zal zijn, binnen het docker bridge-netwerk dat we noemden.
Een eenvoudige berichtenstroom uitvoeren
Om Kafka te laten werken, moeten we er een onderwerp in maken. De producerende klanten kunnen vervolgens gegevensstromen (berichten) publiceren naar het genoemde onderwerp en consumenten kunnen de genoemde gegevensstroom lezen, als ze zijn geabonneerd op dat specifieke onderwerp.
Hiervoor moeten we een interactieve terminal starten met de Kafka-container. Maak een lijst van de containers om de naam van de kafka-container op te halen. In dit geval heet onze container bijvoorbeeld apache-kafka_kafka_1
$ docker psMet de naam van de kafka-container kunnen we nu in deze container vallen.
$ docker exec -it apache-kafka_kafka_1 bashbash-4.4#
Open twee van dergelijke verschillende terminals om er een als consument en een andere producent te gebruiken.
Producentzijde
Voer in een van de prompts (degene die u kiest om producer te zijn) de volgende opdrachten in:
## Een nieuw onderwerp maken met de naam testbash-4.4# kafka-onderwerpen.sh --create --zookeeper zookeeper:2181 --replicatiefactor 1
--partities 1 --topic test
## Een producer starten die datastream publiceert van standaardinvoer naar kafka
bash-4.4# kafka-console-producer.sh --broker-list localhost:9092 --topic test
>
De producent is nu klaar om invoer van het toetsenbord te nemen en deze te publiceren.
Consumentenkant:
Ga door naar de tweede terminal die is aangesloten op uw kafka-container. De volgende opdracht start een consument die zich voedt met het testonderwerp:
$ kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTerug naar Producent
U kunt nu berichten typen in de nieuwe prompt en elke keer dat u op Return drukt, wordt de nieuwe regel afgedrukt in de consumentenprompt. Bijvoorbeeld:
> Dit is een bericht.Dit bericht wordt via Kafka naar de consument verzonden en u kunt het zien afgedrukt bij de prompt van de consument.
Echte instellingen
Je hebt nu een globaal beeld van hoe de Kafka-setup werkt. Voor uw eigen gebruik moet u een hostnaam instellen die niet localhost is, u hebt meerdere van dergelijke makelaars nodig om deel uit te maken van uw kafka-cluster en ten slotte moet u consumenten- en producentenclients instellen.
Hier zijn een paar handige links:
- Confluent's Python-client
- Officiële documentatie
- Een handige lijst met demo's
Ik wens je veel plezier bij het verkennen van Apache Kafka.


