Stel dat u de eigenaar bent van een grote proviandwinkel in de provincie waar u woont. Stel dat u in een groot gebied woont, wat geen commercieel gebied is. Je bent niet de enige met een proviandwinkel in de buurt; je hebt een paar concurrenten. En dan komt het bij je op dat je de telefoonnummers van je klanten moet noteren in een werkboek. Het werkboek is natuurlijk klein en je kunt niet alle telefoonnummers van al je klanten opnemen.
U besluit dus alleen de telefoonnummers van uw vaste klanten op te nemen. En zo heb je een tabel met twee kolommen. De kolom aan de linkerkant heeft de namen van klanten en de kolom aan de rechterkant heeft de bijbehorende telefoonnummers. Op deze manier is er een mapping tussen klantnamen en telefoonnummers. De rechterkolom van de tabel kan worden beschouwd als de kernhashtabel. Klantennamen worden nu sleutels genoemd en de telefoonnummers worden waarden genoemd. Houd er rekening mee dat wanneer een klant overstapt, u zijn rij moet annuleren, zodat de rij leeg kan worden of vervangen kan worden door die van een nieuwe vaste klant. Houd er ook rekening mee dat met de tijd het aantal vaste klanten kan toenemen of afnemen, en dus de tafel kan groeien of krimpen.
Als een ander voorbeeld van in kaart brengen, neem aan dat er een club boeren in een provincie is. Natuurlijk zullen niet alle boeren lid zijn van de club. Sommige leden van de club zullen geen gewone leden zijn (aanwezigheid en bijdrage). De barman kan besluiten de namen van de leden en hun drankkeuze vast te leggen. Hij ontwikkelt een tabel met twee kolommen. In de linkerkolom schrijft hij de namen van de clubleden. In de rechterkolom schrijft hij de bijbehorende drankkeuze.
Er is hier een probleem: er zijn duplicaten in de rechterkolom. Dat wil zeggen, dezelfde naam van een drankje wordt meer dan eens gevonden. Met andere woorden, verschillende leden drinken dezelfde zoete drank of dezelfde alcoholische drank, terwijl andere leden een andere zoete of alcoholische drank drinken. De barman besluit dit probleem op te lossen door een smalle kolom tussen de twee kolommen in te voegen. In deze middelste kolom, vanaf de bovenkant beginnend, nummert hij de rijen vanaf nul (i.e. 0, 1, 2, 3, 4, enz.), naar beneden, één index per rij. Hiermee is zijn probleem opgelost, aangezien de naam van een lid nu wordt toegewezen aan een index, en niet aan de naam van een drankje. Dus als een drankje wordt geïdentificeerd door een index, wordt de naam van een klant toegewezen aan de bijbehorende index.
De kolom met waarden (drankjes) alleen vormt de basishashtabel. In de gewijzigde tabel vormen de kolom met indices en de bijbehorende waarden (met of zonder duplicaten) een normale hashtabel - de volledige definitie van een hashtabel wordt hieronder gegeven. De sleutels (eerste kolom) maken niet noodzakelijkerwijs deel uit van de hashtabel.
Als een ander voorbeeld, beschouw een netwerkserver waar een gebruiker vanaf zijn clientcomputer wat informatie kan toevoegen, wat informatie kan verwijderen of wat informatie kan wijzigen. Er zijn veel gebruikers voor de server. Elke gebruikersnaam komt overeen met een wachtwoord dat op de server is opgeslagen. Degenen die de server onderhouden, kunnen de gebruikersnamen en het bijbehorende wachtwoord zien en kunnen zo het werk van de gebruikers beschadigen.
Dus de eigenaar van de server besluit een functie te maken die een wachtwoord versleutelt voordat het wordt opgeslagen. Een gebruiker logt in op de server, met zijn normaal begrepen wachtwoord. Nu wordt elk wachtwoord echter in gecodeerde vorm opgeslagen. Als iemand een gecodeerd wachtwoord ziet en probeert in te loggen met het, zal het niet werken, omdat inloggen, een begrepen wachtwoord ontvangt van de server en geen gecodeerd wachtwoord.
In dit geval is het begrepen wachtwoord de sleutel en het versleutelde wachtwoord de waarde. Als het versleutelde wachtwoord in een kolom met versleutelde wachtwoorden staat, dan is die kolom een standaard hashtabel. Als die kolom wordt voorafgegaan door een andere kolom met indices die bij nul beginnen, zodat elk versleuteld wachtwoord is gekoppeld aan een index, dan vormen zowel de kolom met indices als de versleutelde wachtwoordkolom een normale hashtabel. De sleutels maken niet noodzakelijkerwijs deel uit van de hashtabel.
Merk in dit geval op dat elke sleutel, die een begrepen wachtwoord is, overeenkomt met een gebruikersnaam. Er is dus een gebruikersnaam die overeenkomt met een sleutel die is toegewezen aan een index, die is gekoppeld aan een waarde die een gecodeerde sleutel is.
De definitie van een hash-functie, de volledige definitie van een hash-tabel, de betekenis van een array en andere details worden hieronder gegeven. Je moet kennis hebben van pointers (referenties) en gelinkte lijsten om de rest van deze tutorial te kunnen waarderen.
Betekenis van hashfunctie en hashtabel
Array
Een array is een reeks opeenvolgende geheugenlocaties. Alle locaties zijn even groot. De waarde op de eerste locatie is toegankelijk met de index, 0; de waarde op de tweede locatie wordt benaderd met de index, 1; de derde waarde is toegankelijk met de index, 2; vierde met index, 3; enzovoorts. Een array kan normaal gesproken niet vergroten of verkleinen. Om de grootte (lengte) van een array te wijzigen, moet een nieuwe array worden gemaakt en de bijbehorende waarden worden gekopieerd naar de nieuwe array. De waarden van een array zijn altijd van hetzelfde type.
Hash-functie
In software is een hash-functie een functie die een sleutel nodig heeft en een overeenkomstige index voor een matrixcel produceert. De array heeft een vaste grootte (vaste lengte). Het aantal sleutels is van willekeurige grootte, meestal groter dan de grootte van de array. De index die resulteert uit de hash-functie wordt een hash-waarde of een digest of een hash-code of gewoon een hash genoemd.
Hash-tabel
Een hashtabel is een array met waarden, waaraan de indices, sleutels zijn toegewezen. De sleutels zijn indirect toegewezen aan de waarden. In feite wordt gezegd dat de sleutels zijn toegewezen aan de waarden, omdat elke index is gekoppeld aan een waarde (met of zonder duplicaten). Echter, de functie die mapping doet (i.e. hashing) relateert sleutels aan de array-indexen en niet echt aan de waarden, omdat er duplicaten in de waarden kunnen zijn. Het volgende diagram illustreert een hashtabel voor de namen van mensen en hun telefoonnummers. De matrixcellen (slots) worden buckets genoemd.
Merk op dat sommige emmers leeg zijn. Een hashtabel hoeft niet per se waarden in al zijn buckets te hebben. De waarden in de buckets hoeven niet per se in oplopende volgorde te staan. De indices waaraan ze zijn gekoppeld, staan echter in oplopende volgorde. De pijlen geven de mapping aan. Merk op dat de sleutels niet in een array staan. Ze hoeven in geen enkele structuur te zijn. Een hash-functie neemt een willekeurige sleutel en hasht een index voor een array uit. Als er geen waarde is in de bucket die is gekoppeld aan de index-hash, kan een nieuwe waarde in die bucket worden geplaatst. De logische relatie is tussen de sleutel en de index, en niet tussen de sleutel en de waarde die bij de index hoort.
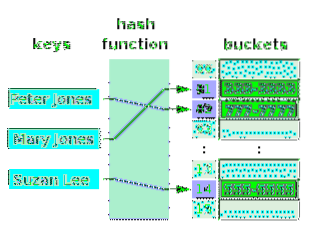
De waarden van een array, zoals die van deze hashtabel, zijn altijd van hetzelfde gegevenstype. Een hashtabel (buckets) kan sleutels verbinden met de waarden van verschillende gegevenstypen. In dit geval zijn de waarden van de array allemaal pointers, die verwijzen naar verschillende waardetypes.
Een hashtabel is een array met een hashfunctie. De functie neemt een sleutel en hasht een bijbehorende index, en verbindt zo sleutels met waarden in de array. De sleutels hoeven geen deel uit te maken van de hashtabel.
Waarom een array en geen gekoppelde lijst voor hash-tabel?
De array voor een hash-tabel kan worden vervangen door een gegevensstructuur met een gekoppelde lijst, maar er zou een probleem zijn. Het eerste element van een gekoppelde lijst is natuurlijk op index, 0; het tweede element is natuurlijk op index, 1; de derde is natuurlijk op index, 2; enzovoorts. Het probleem met de gekoppelde lijst is dat om een waarde op te halen, de lijst moet worden herhaald, en dit kost tijd. Toegang tot een waarde in een array is door willekeurige toegang. Zodra de index bekend is, wordt de waarde verkregen zonder iteratie; deze toegang is sneller.
Botsing
De hash-functie neemt een sleutel en hasht de bijbehorende index, om de bijbehorende waarde te lezen of om een nieuwe waarde in te voegen. Als het de bedoeling is om een waarde te lezen, is er tot nu toe geen probleem (geen probleem). Als het echter de bedoeling is om een waarde in te voegen, kan de gehashte index al een bijbehorende waarde hebben, en dat is een botsing; de nieuwe waarde kan niet worden geplaatst waar er al een waarde is. Er zijn manieren om botsingen op te lossen - zie hieronder.
Waarom een botsing optreedt?
In het voorbeeld van de proviandwinkel hierboven zijn de namen van de klanten de sleutels en de namen van de drankjes de waarden. Merk op dat er te veel klanten zijn, terwijl de array een beperkte grootte heeft en niet alle klanten kan opnemen. Dus alleen de drankjes van vaste klanten worden in de array opgeslagen. De botsing zou optreden wanneer een niet-vaste klant een vaste klant wordt. Klanten voor de winkel vormen een grote set, terwijl het aantal emmers voor klanten in de array beperkt is.
Bij hashtabellen zijn het de waarden voor de sleutels die zeer waarschijnlijk zijn, die worden vastgelegd. Wanneer een sleutel die niet waarschijnlijk was, waarschijnlijk wordt, zou er waarschijnlijk een botsing zijn. In feite vindt er altijd een botsing plaats met hashtabellen.
Basisprincipes van botsingsresolutie
Twee benaderingen voor het oplossen van botsingen worden afzonderlijke ketens en open adressering genoemd. In theorie zouden de sleutels niet in de datastructuur moeten staan of geen deel mogen uitmaken van de hashtabel. Beide benaderingen vereisen echter dat de sleutelkolom voorafgaat aan de hashtabel en onderdeel wordt van de algehele structuur. In plaats van dat sleutels in de sleutelkolom staan, kunnen verwijzingen naar de sleutels in de sleutelkolom staan.
Een praktische hashtabel bevat een sleutelkolom, maar deze sleutelkolom maakt officieel geen deel uit van de hashtabel.
Beide benaderingen voor resolutie kunnen lege buckets hebben, niet noodzakelijk aan het einde van de array.
Afzonderlijke Chaining
In afzonderlijke ketens, wanneer een botsing optreedt, wordt de nieuwe waarde toegevoegd aan de rechterkant (niet boven of onder) van de gebotste waarde. Dus twee of drie waarden hebben uiteindelijk dezelfde index. Zelden zouden meer dan drie dezelfde index moeten hebben.
Kunnen meer dan één waarde echt dezelfde index in een array hebben?? - Nee. Dus in veel gevallen is de eerste waarde voor de index een verwijzing naar een gelinkte lijstgegevensstructuur, die de één, twee of drie gebotste waarden bevat. Het volgende diagram is een voorbeeld van een hashtabel voor het afzonderlijk koppelen van klanten en hun telefoonnummers:
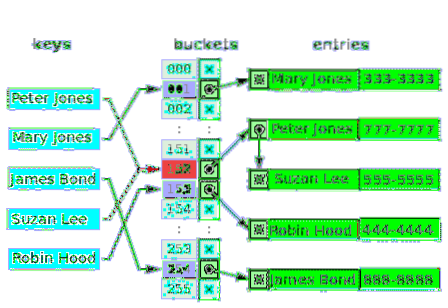
De lege emmers zijn gemarkeerd met de letter x. De rest van de slots hebben verwijzingen naar gekoppelde lijsten. Elk element van de gekoppelde lijst heeft twee gegevensvelden: één voor de naam van de klant en de andere voor het telefoonnummer. Er treedt een conflict op voor de toetsen: Peter Jones en Suzan Lee. De corresponderende waarden bestaan uit twee elementen van één gekoppelde lijst.
Voor conflicterende sleutels is het criterium om waarde in te voegen hetzelfde criterium dat wordt gebruikt om de waarde te lokaliseren (en te lezen).
Adressering openen
Bij open adressering worden alle waarden opgeslagen in de bucket-array. Wanneer er een conflict optreedt, wordt de nieuwe waarde ingevoegd in een lege emmer, nieuwe de overeenkomstige waarde voor het conflict, volgens een bepaald criterium. Het criterium dat wordt gebruikt om een waarde in te voegen bij een conflict is hetzelfde criterium dat wordt gebruikt om de waarde te lokaliseren (zoeken en lezen).
Het volgende diagram illustreert conflictoplossing met open adressering:
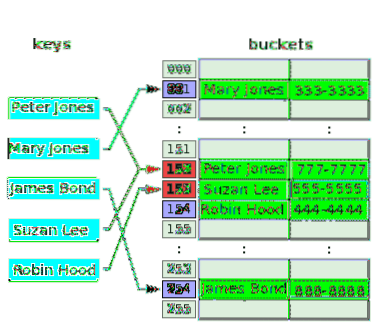 De hash-functie neemt de sleutel, Peter Jones en hasht de index, 152, en slaat zijn telefoonnummer op in de bijbehorende bucket. Na enige tijd hasht de hash-functie dezelfde index, 152 van de sleutel, Suzan Lee, die botst met de index voor Peter Jones. Om dit op te lossen, wordt de waarde voor Suzan Lee opgeslagen in de bucket van de volgende index, 153, die leeg was. De hash-functie hasht de index, 153 voor de sleutel, Robin Hood, maar deze index is al gebruikt om het conflict voor een vorige sleutel op te lossen. Dus de waarde voor Robin Hood wordt in de volgende lege emmer geplaatst, die van index 154.
De hash-functie neemt de sleutel, Peter Jones en hasht de index, 152, en slaat zijn telefoonnummer op in de bijbehorende bucket. Na enige tijd hasht de hash-functie dezelfde index, 152 van de sleutel, Suzan Lee, die botst met de index voor Peter Jones. Om dit op te lossen, wordt de waarde voor Suzan Lee opgeslagen in de bucket van de volgende index, 153, die leeg was. De hash-functie hasht de index, 153 voor de sleutel, Robin Hood, maar deze index is al gebruikt om het conflict voor een vorige sleutel op te lossen. Dus de waarde voor Robin Hood wordt in de volgende lege emmer geplaatst, die van index 154.
Methoden voor het oplossen van conflicten voor afzonderlijke ketens en open adressering
Gescheiden ketenen heeft zijn methoden om conflicten op te lossen, en open adressering heeft ook zijn eigen methoden om conflicten op te lossen.
Methoden voor het oplossen van afzonderlijke ketenconflicten
De methoden voor het apart koppelen van hashtabellen worden nu kort uitgelegd:
Afzonderlijke ketens met gekoppelde lijsten
Deze methode is zoals hierboven uitgelegd:. Elk element van de gekoppelde lijst hoeft echter niet noodzakelijk het sleutelveld te hebben (e.g. veld klantnaam hierboven).
Afzonderlijke ketens met lijstkopcellen
Bij deze methode wordt het eerste element van de gekoppelde lijst opgeslagen in een bucket van de array. Dit is mogelijk als het gegevenstype voor de array het element van de gekoppelde lijst is.
Afzonderlijke ketenen met andere structuren
Elke andere gegevensstructuur, zoals de zelfbalancerende binaire zoekboom die de vereiste bewerkingen ondersteunt, kan worden gebruikt in plaats van de gekoppelde lijst - zie later.
Methoden voor het oplossen van open adresconflicten
Een methode voor het oplossen van conflicten in open adressering wordt probe-sequentie genoemd. Drie bekende probesequenties worden nu kort uitgelegd:
Lineair sonderen
Bij lineair sonderen wordt bij een conflict gezocht naar de dichtstbijzijnde lege emmer onder de emmer bij conflict conflict. Bij lineair tasten worden zowel de sleutel als de waarde ervan in dezelfde bucket opgeslagen.
Kwadratisch sonderen
Neem aan dat conflict optreedt bij index H. Het volgende lege slot (emmer) bij index H + 12 is gebruikt; als die al bezet is, dan de volgende lege op H + 22 wordt gebruikt, als die al bezet is, dan de volgende lege op H + 32 wordt gebruikt, enzovoort. Hier zijn varianten op.
Dubbele hashing
Bij dubbele hashing zijn er twee hashfuncties. De eerste berekent (hasht) de index. Als er een conflict optreedt, gebruikt de tweede dezelfde sleutel om te bepalen hoe ver de waarde moet worden ingevoegd. Er is meer aan de hand - zie later.
Perfecte hash-functie
Een perfecte hash-functie is een hash-functie die niet kan leiden tot een botsing. Dit kan gebeuren wanneer de set sleutels relatief klein is en elke sleutel wordt toegewezen aan een bepaald geheel getal in de hashtabel.
In ASCII-tekenset kunnen hoofdletters worden toegewezen aan de bijbehorende kleine letters met behulp van een hash-functie. Letters worden in het computergeheugen weergegeven als cijfers. In ASCII-tekenset is A 65, B 66, C 67, enz. en a is 97, b is 98, c is 99, enz. Om van A naar a te mappen, tel je 32 op bij 65; om van B naar b in kaart te brengen, voeg 32 toe aan 66; om van C naar c in kaart te brengen, voeg 32 toe aan 67; enzovoorts. Hier zijn de hoofdletters de sleutels en de kleine letters de waarden. De hashtabel hiervoor kan een array zijn waarvan de waarden de bijbehorende indices zijn. Onthoud dat buckets van de array leeg kunnen zijn. Dus buckets in de array van 64 tot 0 kunnen leeg zijn. De hash-functie voegt eenvoudig 32 toe aan het codenummer in hoofdletters om de index te verkrijgen, en dus de kleine letter. Zo'n functie is een perfecte hashfunctie.
Hashing van geheel getal naar geheel getal indices
Er zijn verschillende methoden om integer te hashen. Een daarvan heet de Modulo Division Method (Function).
De hashfunctie van de Modulo Division
Een functie in computersoftware is geen wiskundige functie. In informatica (software) bestaat een functie uit een reeks uitspraken voorafgegaan door argumenten. Voor de functie Modulo Division zijn de sleutels gehele getallen en worden ze toegewezen aan indices van de reeks buckets. De set sleutels is groot, dus alleen sleutels die zeer waarschijnlijk in de activiteit zullen voorkomen, worden in kaart gebracht. Er treden dus botsingen op wanneer onwaarschijnlijke sleutels moeten worden toegewezen.
In de verklaring,
20 / 6 = 3R2
20 is het deeltal, 6 is de deler en 3 rest 2 is het quotiënt. De rest 2 wordt ook wel de modulo . genoemd. Let op: het is mogelijk om een modulo van 0 . te hebben.
Voor deze hashing is de tafelgrootte meestal een macht van 2, e.g. 64 = 26 of 256 = 28, enz. De deler voor deze hash-functie is een priemgetal dichtbij de arraygrootte. Deze functie deelt de sleutel door de deler en retourneert de modulo. De modulo is de index van de reeks emmers. De bijbehorende waarde in de bucket is een waarde naar keuze (waarde voor de sleutel).
Toetsen met variabele lengte hashen
Hier zijn sleutels van de sleutelset teksten van verschillende lengtes. Er kunnen verschillende gehele getallen in het geheugen worden opgeslagen met hetzelfde aantal bytes (de grootte van een Engels teken is een byte). Wanneer verschillende sleutels verschillende bytegroottes hebben, wordt gezegd dat ze van variabele lengte zijn. Een van de methoden voor het hashen van variabele lengtes wordt Radix Conversion Hashing genoemd.
Radix conversie hashing
In een string is elk teken in de computer een getal. Bij deze methode:,
Hashcode (index) = x0eenk−1+X1eenk−2+… +xk−2een1+Xk−1een0
Waarbij (x0, x1,… , xk−1) de karakters van de invoerstring zijn en a een radix is, e.g. 29 (zie verderop). k is het aantal karakters in de string. Er is meer aan de hand - zie later.
Sleutels en waarden
In een sleutel/waarde-paar hoeft een waarde niet per se een getal of tekst te zijn. Het kan ook een record zijn. Een record is een horizontaal geschreven lijst. In een sleutel/waarde-paar kan elke sleutel in feite verwijzen naar een andere tekst of nummer of record.
Associatieve matrix
Een lijst is een gegevensstructuur, waarbij de lijstitems gerelateerd zijn, en er is een reeks bewerkingen die op de lijst werken. Elk lijstitem kan uit een paar items bestaan. De algemene hashtabel met zijn sleutels kan worden beschouwd als een gegevensstructuur, maar het is meer een systeem dan een gegevensstructuur. De sleutels en de bijbehorende waarden zijn niet erg afhankelijk van elkaar. Ze zijn niet erg verwant aan elkaar.
Aan de andere kant is een associatieve array iets soortgelijks, maar sleutels en hun waarden zijn erg afhankelijk van elkaar; ze zijn erg verwant aan elkaar. U kunt bijvoorbeeld een associatieve reeks fruit en hun kleuren hebben. Elke vrucht heeft van nature zijn kleur. De naam van de vrucht is de sleutel; de kleur is de waarde. Tijdens het invoegen wordt elke sleutel ingevoegd met zijn waarde. Bij het verwijderen wordt elke sleutel verwijderd met zijn waarde.
Een associatieve array is een hash-tabelgegevensstructuur die is samengesteld uit sleutel/waarde-paren, waarbij er geen duplicaat is voor de sleutels. De waarden kunnen duplicaten hebben. In deze situatie maken de sleutels deel uit van de structuur. Dat wil zeggen, de sleutels moeten worden opgeslagen, terwijl bij de algemene hast-tabel de sleutels niet hoeven te worden opgeslagen. Het probleem van de gedupliceerde waarden wordt natuurlijk opgelost door de indices van de reeks emmers. Verwar niet tussen dubbele waarden en botsing bij een index.
Aangezien een associatieve array een gegevensstructuur is, heeft deze ten minste de volgende bewerkingen:
Associatieve matrixbewerkingen
invoegen of toevoegen
Hiermee wordt een nieuw sleutel/waarde-paar in de verzameling ingevoegd, waarbij de sleutel wordt toegewezen aan zijn waarde.
opnieuw toewijzen
Deze bewerking vervangt de waarde van een bepaalde sleutel door een nieuwe waarde.
verwijderen of verwijderen
Dit verwijdert een sleutel plus de bijbehorende waarde.
opzoeken
Deze bewerking zoekt naar de waarde van een bepaalde sleutel en retourneert de waarde (zonder deze te verwijderen).
Conclusie
Een hash-tabelgegevensstructuur bestaat uit een array en een functie. De functie wordt een hash-functie genoemd. De functie wijst sleutels toe aan waarden in de array via de indices van de array. De sleutels hoeven niet noodzakelijkerwijs deel uit te maken van de gegevensstructuur. De sleutelset is meestal groter dan de opgeslagen waarden. Wanneer er een botsing optreedt, wordt deze opgelost door de afzonderlijke ketenbenadering of de open adresseringsbenadering. Een associatieve array is een speciaal geval van de hash-tabelgegevensstructuur.


