Syntaxis
Grep [patroon] [bestandsnaam]
Na het gebruik van grep komt er een patroon. Het patroon impliceert de manier waarop we het willen gebruiken bij het verwijderen van extra ruimte in de gegevens. Na het patroon wordt de bestandsnaam beschreven waarmee het patroon wordt uitgevoerd.
Voorwaarde
Om het nut van grep gemakkelijk te begrijpen, moeten we Ubuntu op ons systeem hebben geïnstalleerd. Geef gebruikersgegevens op door gebruikersnaam en wachtwoord op te geven om privileges te hebben voor toegang tot de applicaties van Linux. Open na het inloggen de applicatie en zoek naar een terminal of gebruik de sneltoets ctrl+alt+T.
Door [: blank:] Trefwoord te gebruiken
Stel dat we een bestand hebben met de naam bfile met een tekstextensie. U kunt een bestand maken in de teksteditor of met een opdrachtregel in de terminal. Een bestand maken op de terminal, inclusief de volgende opdrachten:.
$ Echo "tekst die in een bestand moet worden ingevoerd" > bestandsnaam.tekstHet is niet nodig om een bestand aan te maken als het al aanwezig is. Geef het gewoon weer met de toegevoegde opdracht:
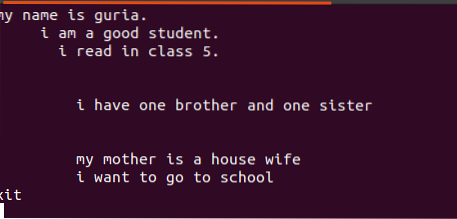
$ echo bestandsnaam.tekstTekst die in deze bestanden is geschreven, bevat spaties ertussen, zoals te zien is in de onderstaande afbeelding.
![]()
Deze lege regels kunnen worden verwijderd met een lege opdracht om lege spaties tussen de woorden of tekenreeksen te negeren.
$ egrep '^[[:blank]]*[^[:blank:]#]' bbestand.tekst![]()
Na het toepassen van de query worden de lege spaties tussen de regels verwijderd en bevat de uitvoer geen extra spatie meer. Het eerste woord wordt gemarkeerd als spaties tussen het laatste woord van de regel en tussen de eerste woorden van de volgende regel worden verwijderd. We kunnen ook voorwaarden toepassen op hetzelfde grep-commando door deze lege functie toe te voegen om nutteloze ruimte in de uitvoer te verwijderen.
Door [: spatie:] te gebruiken
Een ander voorbeeld van het negeren van ruimte wordt hier uitgelegd explained.
Zonder bestandsextensie te vermelden, zullen we eerst het bestaande bestand weergeven met het commando.
$ kattenbestand20![]()
Laten we eens kijken hoe extra ruimte wordt verwijderd met behulp van het grep-commando naast het [:space:] sleutelwoord. De -v-optie van Grep helpt bij het afdrukken van regels zonder lege regels en extra spatiëring die ook in een alineaformulier is opgenomen.
$ grep -v '^[[;spatie:]]*$' bestand20U zult zien dat extra regels worden verwijderd en dat de uitvoer regelgewijs in volgorde is. Dat is hoe grep -v-methodologie zo nuttig is om het vereiste doel te bereiken.
![]()
Het noemen van bestandsextensies beperkt de grep-functionaliteit om alleen uit te voeren op de specifieke bestandsextensies, i.e., .tekst of .mp3. Als we een uitlijning uitvoeren op een tekstbestand, nemen we fileg.txt als voorbeeldbestand. Eerst zullen we de daarin aanwezige tekst weergeven met behulp van de $ cat-functie. Uitvoer is als volgt:
![]()
Door de opdracht toe te passen, is ons uitvoerbestand verkregen. Hier kunnen we gegevens zien zonder spatiëring tussen de regels die opeenvolgend zijn geschreven.
$ grep -v '^[[:space:]]*$' fileg.tekst![]()
Naast lange commando's, kunnen we ook de korte geschreven commando's in Linux en Unix gebruiken om grep ondersteunt steno-tekens erin te implementeren.
$ grep '\s' bestandsnaam.tekstWe hebben gezien hoe de uitvoer wordt verkregen door commando's van de invoer toe te passen. Hier zullen we leren hoe input wordt behouden van de output.
$ grep '\S' bestandsnaam.txt > tmp.txt && mv tmp.txt-bestandsnaam.tekstHier gebruiken we een tijdelijk tekstbestand met de tekstextensie tmp.
Door ^# te gebruiken
Net zoals andere beschreven voorbeelden, zullen we het commando op het tekstbestand toepassen met het cat commando cat. We kunnen ook tekst weergeven met het echo-commando.
$ echo bestandsnaam.tekstHet tekstbestand bevat 4 regels, met ruimte ertussen. Deze spatielijnen kunnen eenvoudig worden verwijderd met een bepaald commando.
![]()
Reguliere uitgebreide bewerkingen worden mogelijk gemaakt door -E, waarmee alle reguliere expressies mogelijk zijn, vooral pipe. Een pijp wordt gebruikt als een optionele "of"-conditie in elk patroon.”^#”. Dit toont de overeenkomst van tekstregels in het bestand dat begint met het teken #. "^$" komt overeen met alle vrije spaties in de tekst of lege regels.
![]()
De uitvoer toont de volledige verwijdering van extra ruimte tussen de regels in het gegevensbestand the. In dit voorbeeld hebben we gezien dat in het commando dat ”^#” eerst komt, wat betekent dat de tekst als eerste overeenkomt. "^$" komt na | operator, zodat de vrije ruimte achteraf wordt aangepast.
Door ^$ . te gebruiken
Net als het hierboven genoemde voorbeeld, zullen we met dezelfde resultaten komen omdat de opdracht bijna hetzelfde is. Het patroon is echter omgekeerd geschreven written. Bestand22.txt is een bestand dat we gaan gebruiken bij het verwijderen van spaties.
![]()
Dezelfde methodiek wordt toegepast behalve het werken met prioriteit. Volgens deze opdracht worden eerst vrije spaties vergeleken en vervolgens worden de tekstbestanden aangepast. De uitvoer levert een reeks regels op door extra gaten erin te verwijderen.
![]()
Andere eenvoudige opdrachten
- Grep '^…' bestandsnaam.
- grep'.' Bestandsnaam
Deze zijn allebei zo eenvoudig en helpen bij het verwijderen van hiaten in tekstregels.
Conclusie
Het verwijderen van nutteloze hiaten in bestanden met behulp van reguliere expressies is een vrij eenvoudige benadering om een soepele reeks gegevens te verkrijgen en consistentie te behouden. Voorbeelden worden op een gedetailleerde manier uitgelegd om uw informatie over het onderwerp te verbeteren.


