Indices zijn gespecialiseerde zoektabellen die worden gebruikt door zoekmachines voor databanken om zoekopdrachtresultaten te versnellen. Een index is een verwijzing naar de informatie in een tabel. Als de namen in een contactenboek bijvoorbeeld niet alfabetisch zijn, moet u elke rij naar beneden gaan en elke naam doorzoeken voordat u het specifieke telefoonnummer bereikt waarnaar u zoekt. Een index versnelt de SELECT-commando's en WHERE-frases en voert gegevensinvoer uit in de UPDATE- en INSERT-commando's. Ongeacht of indexen worden ingevoegd of verwijderd, er is geen invloed op de informatie in de tabel. Indexen kunnen op dezelfde manier speciaal zijn als de UNIEKE beperking helpt om replicarecords te vermijden in het veld of de set velden waarvoor de index bestaat.
Algemene syntaxis
De volgende algemene syntaxis wordt gebruikt om indexen te maken:.
>> CREATE INDEX index_name ON table_name (column_name);Om aan indexen te werken, opent u de pgAdmin van Postgresql vanuit de toepassingsbalk. U vindt de optie 'Servers' hieronder weergegeven. Klik met de rechtermuisknop op deze optie en verbind deze met de database.
Zoals u kunt zien, wordt de database 'Test' vermeld in de optie 'Databases'. Als u er geen heeft, klikt u met de rechtermuisknop op 'Databases', navigeert u naar de optie 'Maken' en geeft u de database een naam volgens uw voorkeuren.
Vouw de optie 'Schema's' uit en u zult de optie 'Tabellen' daar vinden. Als je er geen hebt, klik er dan met de rechtermuisknop op, ga naar 'Maken' en klik op de optie 'Tabel' om een nieuwe tabel te maken. Aangezien we de tabel 'emp' al hebben gemaakt, kunt u deze in de lijst zien.
Probeer de SELECT-query in de Query-editor om de records van de 'emp'-tabel op te halen, zoals hieronder weergegeven.
>> KIES * VAN openbaar.emp BESTELLEN DOOR “id” ASC;
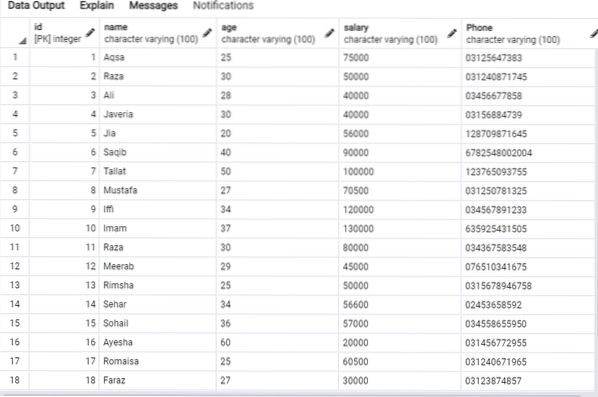
De volgende gegevens staan in de 'emp'-tabel.
Indexen met één kolom maken
Vouw de 'emp'-tabel uit om verschillende categorieën te vinden, e.g., Kolommen, beperkingen, indexen, enz. Klik met de rechtermuisknop op 'Indexen', navigeer naar de optie 'Maken' en klik op 'Index' om een nieuwe index te maken.
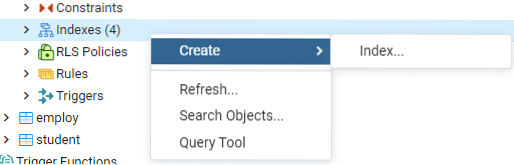
Construeer een index voor de gegeven 'emp'-tabel, of eventuated display, met behulp van het Index-dialoogvenster. Hier zijn er twee tabbladen: 'Algemeen' & 'Definitie.' Voeg op het tabblad 'Algemeen' een specifieke titel voor de nieuwe index in het veld 'Naam' in. Kies de 'tablespace' waaronder de nieuwe index zal worden opgeslagen met behulp van de vervolgkeuzelijst naast 'Tablespace'.' Maak hier, net als in het gedeelte 'Opmerkingen', indexopmerkingen. Om dit proces te starten, gaat u naar het tabblad 'Definitie'.
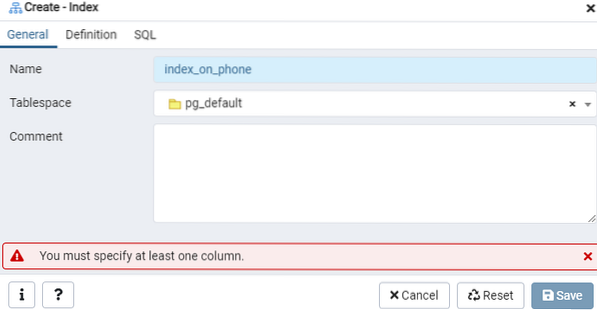
Geef hier de 'Toegangsmethode' op door het indextype te selecteren. Daarna, om uw index als 'Uniek' te maken, zijn er verschillende andere opties die daar worden vermeld. Tik in het gebied 'Kolommen' op het '+'-teken en voeg de kolomnamen toe die voor indexering moeten worden gebruikt. Zoals u kunt zien, hebben we indexering alleen toegepast op de kolom 'Telefoon'. Selecteer om te beginnen de sectie SQL.
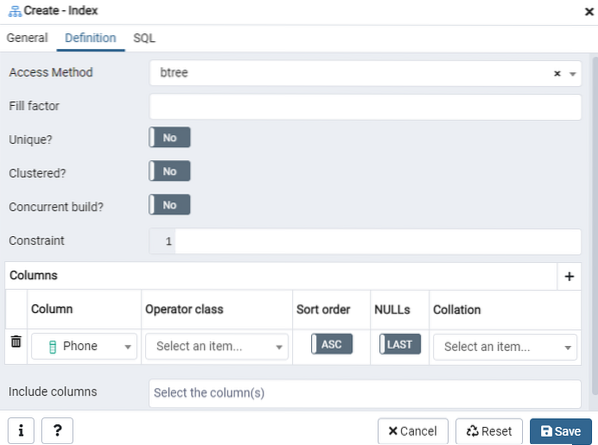
Het tabblad SQL toont het SQL-commando dat is gemaakt door uw invoer in het dialoogvenster Index. Klik op de knop 'Opslaan' om de index te maken.
Nogmaals, ga naar de optie 'Tabellen' en navigeer naar de tabel 'emp'. Vernieuw de optie 'Indexen' en u zult de nieuw gemaakte 'index_on_phone'-index erin vinden.
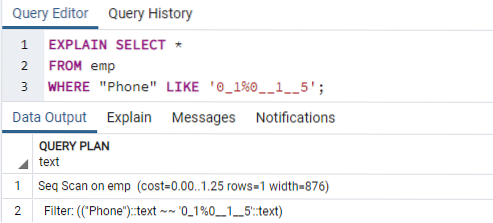
Nu zullen we het EXPLAIN SELECT-commando uitvoeren om de resultaten voor de indexen te controleren met de WHERE-component. Dit zal resulteren in de volgende uitvoer, die zegt: 'Seq Scan on emp'.' Je vraagt je misschien af waarom dit is gebeurd terwijl je indexen gebruikt.
Reden: De Postgres-planner kan om verschillende redenen besluiten geen index te hebben. De strateeg neemt meestal de beste beslissingen, ook al zijn de redenen niet altijd duidelijk. Het is prima als een indexzoekopdracht wordt gebruikt in sommige zoekopdrachten, maar niet in alle. De items die uit beide tabellen worden geretourneerd, kunnen variëren, afhankelijk van de vaste waarden die door de query worden geretourneerd. Omdat dit gebeurt, is een sequentiescan bijna altijd sneller dan een indexscan, wat aangeeft dat de queryplanner misschien gelijk had door te bepalen dat de kosten om de query op deze manier uit te voeren, worden verlaagd.
Meerdere kolomindexen maken
Om indexen met meerdere kolommen te maken, opent u de opdrachtregel-shell en overweegt u de volgende tabel 'student' om aan indexen met meerdere kolommen te werken.
>> KIES * VAN Student;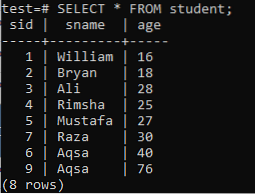
Schrijf de volgende CREATE INDEX-query erin:. Met deze query wordt een index gemaakt met de naam 'new_index' in de kolommen 'sname' en 'age' van de tabel 'student'.
>> MAAK INDEX new_index ON Student (naam, leeftijd);
Nu zullen we de eigenschappen en attributen van de nieuw aangemaakte 'new_index' index weergeven met het '\d' commando. Zoals u op de afbeelding kunt zien, is dit een index van het btree-type die is toegepast op de kolommen 'naam' en 'leeftijd'.
>> \d nieuwe_index;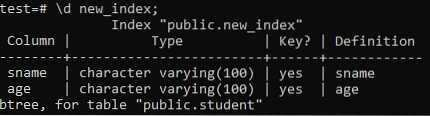
UNIEKE Index maken
Ga uit van de volgende 'emp'-tabel om een unieke index te construeren:.
>> KIES * UIT werk;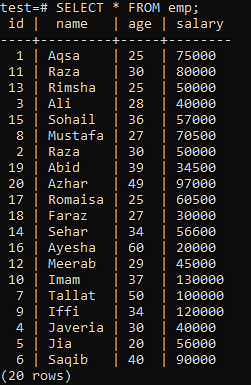
Voer de CREATE UNIQUE INDEX-query uit in de shell, gevolgd door de indexnaam 'empind' in de 'name'-kolom van de 'emp'-tabel. In de uitvoer kunt u zien dat de unieke index niet kan worden toegepast op een kolom met dubbele 'naam'-waarden.
>> MAAK unieke INDEX empind ON emp (naam);
Zorg ervoor dat u de unieke index alleen toepast op kolommen die geen duplicaten bevatten. Voor de tabel 'emp' mag u ervan uitgaan dat alleen de kolom 'id' unieke waarden bevat. We zullen er dus een unieke index op toepassen.
>> MAAK unieke INDEX empind ON werkn (id);
Hieronder volgen de kenmerken van de unieke index:.
>> \d schijn;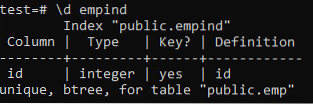
Index laten vallen
De DROP-instructie wordt gebruikt om een index uit een tabel te verwijderen.
>> DROP INDEX empind;
Conclusie
Hoewel indexen zijn ontworpen om de efficiëntie van databases te verbeteren, is het in sommige gevallen niet mogelijk om een index te gebruiken. Bij het gebruik van een index moeten de volgende regels in acht worden genomen:
- Indexen mogen niet worden weggegooid voor kleine tabellen.
- Tabellen met veel grootschalige upgrade-/update- of toevoegings-/invoegbewerkingen.
- Voor kolommen met een aanzienlijk percentage NULL-waarden mogen indexen niet door elkaar lopen-
- uitverkoop.
- Indexering moet worden vermeden bij regelmatig gemanipuleerde kolommen.


