Voorwaarde
U moet de benodigde python-bibliotheek installeren om gegevens uit Kafka . te lezen. Python3 wordt in deze tutorial gebruikt om het script van consument en producent te schrijven. Als het pip-pakket niet eerder in uw Linux-besturingssysteem is geïnstalleerd, moet u pip installeren voordat u de Kafka-bibliotheek voor python installeert. python3-kafka wordt in deze tutorial gebruikt om gegevens uit Kafka . te lezen. Voer de volgende opdracht uit om de bibliotheek te installeren:.
$ pip installeer python3-kafkaEenvoudige tekstgegevens lezen uit Kafka
Er kunnen verschillende soorten gegevens door de producent worden verzonden over een bepaald onderwerp dat door de consument kan worden gelezen. In dit deel van deze tutorial wordt getoond hoe eenvoudige tekstgegevens van Kafka kunnen worden verzonden en ontvangen met behulp van producent en consument.
Maak een bestand met de naam producent1.py met het volgende python-script:. KafkaProducer module wordt geïmporteerd uit de Kafka-bibliotheek. De brokerlijst moet worden gedefinieerd op het moment van initialisatie van het producerobject om verbinding te maken met de Kafka-server. De standaardpoort van Kafka is '9092'. argument bootstrap_servers wordt gebruikt om de hostnaam met de poort te definiëren. 'Eerste_onderwerp' is ingesteld als een onderwerpnaam waarmee een sms-bericht van de producent wordt verzonden. Vervolgens een eenvoudig sms-bericht, 'Hallo van Kafka' wordt verzonden met sturen() methode van KafkaProducer naar het onderwerp, 'Eerste_onderwerp'.
producent1.py:
# Importeer KafkaProducer uit de Kafka-bibliotheekvan kafka import KafkaProducer
# Definieer server met poort
bootstrap_servers = ['localhost:9092']
# Definieer de onderwerpnaam waar het bericht zal worden gepubliceerd
topicName = 'First_Topic'
# Producentvariabele initialiseren
producer = KafkaProducer(bootstrap_servers = bootstrap_servers)
# Publiceer tekst in gedefinieerd onderwerp
producent.send(topicName, b'Hallo van kafka... ')
# Bericht afdrukken
print("Bericht verzonden")
Maak een bestand met de naam consument1.py met het volgende python-script:. KafkaConsument module wordt geïmporteerd uit de Kafka-bibliotheek om gegevens uit Kafka . te lezen. sys module wordt hier gebruikt om het script te beëindigen. Dezelfde hostnaam en poortnummer van de producent worden gebruikt in het script van de consument om gegevens uit Kafka . te lezen. De onderwerpnaam van de consument en de producent moet hetzelfde zijn dat is 'Eerste_onderwerp'. Vervolgens wordt het consumentenobject geïnitialiseerd met de drie argumenten. Onderwerpnaam, groeps-ID en serverinformatie. voor loop wordt hier gebruikt om de tekst te lezen die is verzonden door Kafka producer.
consument1.py:
# Importeer KafkaConsumer uit de Kafka-bibliotheekvan kafka import KafkaConsumer
# Systeemmodule importeren
import systeem
# Definieer server met poort
bootstrap_servers = ['localhost:9092']
# Definieer de onderwerpnaam van waar het bericht zal worden ontvangen
topicName = 'First_Topic'
# Initialiseer consumentenvariabele
consumer = KafkaConsumer (onderwerpnaam, group_id ='group1',bootstrap_servers =
bootstrap_servers)
# Lees en print bericht van consument
voor bericht in consument:
print("Onderwerpnaam=%s,Bericht=%s"%(msg.onderwerp, bericht.waarde))
# Beëindig het script
sys.Uitgang()
Uitgang:
Voer de volgende opdracht uit vanaf één terminal om het producerscript uit te voeren:.
$ python3 producent1.pyDe volgende uitvoer verschijnt na het verzenden van het bericht:.

Voer de volgende opdracht uit vanaf een andere terminal om het consumentenscript uit te voeren:.
$ python3 consument1.pyDe uitvoer toont de naam van het onderwerp en het sms-bericht dat door de producent is verzonden.

JSON-geformatteerde gegevens uit Kafka . lezen
JSON-geformatteerde gegevens kunnen door de Kafka-producent worden verzonden en door Kafka-consument worden gelezen met behulp van: de json module van python. Hoe JSON-gegevens kunnen worden geserialiseerd en gedeserialiseerd voordat de gegevens worden verzonden en ontvangen met behulp van de python-kafka-module, wordt in dit deel van deze zelfstudie getoond.
Maak een python-script met de naam producent2.py met het volgende script. Een andere module met de naam JSON wordt geïmporteerd met KafkaProducer module hier. value_serializer argument wordt gebruikt met bootstrap_servers argument hier om het object van Kafka producer te initialiseren. Dit argument geeft aan dat JSON-gegevens worden gecodeerd met 'utf-8' tekenset op het moment van verzenden. Vervolgens worden JSON-geformatteerde gegevens verzonden naar het onderwerp met de naam JSONonderwerp.
producent2.py:
# Importeer KafkaProducer uit de Kafka-bibliotheekvan kafka import KafkaProducer
# Importeer JSON-module om gegevens te serialiseren
import json
# Initialiseer de producervariabele en stel de parameter in voor JSON-codering
producer = KafkaProducer(bootstrap_servers =
['localhost:9092'],value_serializer=lambda v: json.stortplaatsen (v).coderen('utf-8'))
# Gegevens verzenden in JSON-indeling
producent.send('JSONtopic', 'name': 'fahmida','email':'[email protected]')
# Bericht afdrukken
print("Bericht verzonden naar JSONtopic")
Maak een python-script met de naam consument2.py met het volgende script. KafkaConsument, sys en JSON-modules worden geïmporteerd in dit script. KafkaConsument module wordt gebruikt om JSON-geformatteerde gegevens uit de Kafka . te lezen. JSON-module wordt gebruikt om de gecodeerde JSON-gegevens te decoderen die door de Kafka-producent zijn verzonden. Sys module wordt gebruikt om het script te beëindigen. value_deserializer argument wordt gebruikt met bootstrap_servers om te definiëren hoe JSON-gegevens worden gedecodeerd. De volgende, voor loop wordt gebruikt om alle consumentenrecords en JSON-gegevens af te drukken die zijn opgehaald uit Kafka.
consument2.py:
# Importeer KafkaConsumer uit de Kafka-bibliotheekvan kafka import KafkaConsumer
# Systeemmodule importeren
import systeem
# Importeer json-module om gegevens te serialiseren
import json
# Initialiseer de consumentenvariabele en stel de eigenschap in voor JSON-decodering
consumer = KafkaConsumer ('JSONtopic',bootstrap_servers = ['localhost:9092'],
value_deserializer=lambda m: json.ladingen (m.decoderen('utf-8')))
# Lees gegevens van kafka
voor bericht in consument:
print("Consumentengegevens:\n")
afdrukken (bericht)
print("\nLezen van JSON-gegevens\n")
print("Naam:",bericht[6]['naam'])
print("E-mail:",bericht[6]['e-mail'])
# Beëindig het script
sys.Uitgang()
Uitgang:
Voer de volgende opdracht uit vanaf één terminal om het producerscript uit te voeren:.
$ python3 producent2.pyHet script drukt het volgende bericht af na het verzenden van de JSON-gegevens:.

Voer de volgende opdracht uit vanaf een andere terminal om het consumentenscript uit te voeren:.
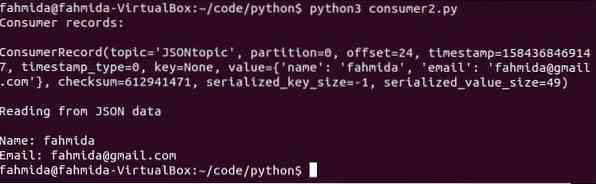
$ python3 consument2.pyDe volgende uitvoer zal verschijnen na het uitvoeren van het script:.
Conclusie:
De gegevens kunnen in verschillende formaten van Kafka worden verzonden en ontvangen met behulp van python. De gegevens kunnen ook worden opgeslagen in de database en worden opgehaald uit de database met behulp van Kafka en python. Ik ben thuis, deze tutorial zal de python-gebruiker helpen om met Kafka . te gaan werken.


