LinuxHint heeft al een tutorial gepubliceerd waarin wordt uitgelegd hoe de training van Tesseract moet worden geïnstalleerd en begrepen.
Deze tutorial toont het installatieproces van Tesseract in Debian/Ubuntu-systemen, maar zal niet uitgebreid worden op trainingsfunctionaliteiten, als je niet bekend bent met deze software, kan het lezen van het genoemde artikel een goede introductie zijn. Vervolgens laten we u zien hoe u een GIF-afbeelding met Tesseract kunt verwerken om de tekst eruit te krijgen.
Tesseract-installatie:
Rennen:
apt installeer tesseract-ocr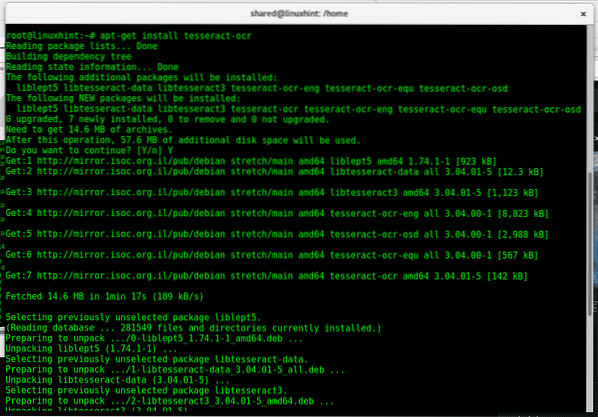
Nu moet je imagemagick installeren, wat een beeldconvertor is.

Eenmaal geïnstalleerd kunnen we Tesseract al testen, om het te testen heb ik een gif gevonden met licentie voor hergebruik.
Laten we nu eens kijken wat er gebeurt als we tesseract uitvoeren op de gif-afbeelding:
tesseract 2002NY40.gif 1 resultaat
Doe nu een "minder" op 1 resultaat.tekst
minder 1 resultaat.tekst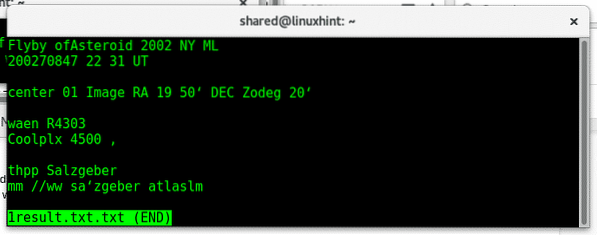
Hier is de afbeelding met de tekst:

De standaardinstellingen van deze Tesseract zijn behoorlijk nauwkeurig, meestal is er training voor nodig om zo'n nauwkeurigheid te krijgen. Laten we een andere gratis afbeelding proberen die ik op Wiki Commons heb gevonden, na het downloaden ervan:
tesseract Actualizar_GNULinux_Terminal_apt-get.gif 2 resultaat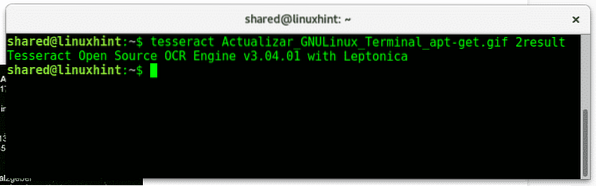
Controleer nu de inhoud van het bestand.
minder 2resultaat.tekst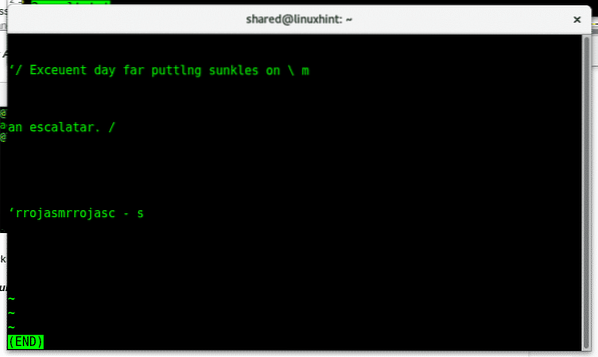
Dat was het resultaat, terwijl de inhoud van de originele afbeelding was: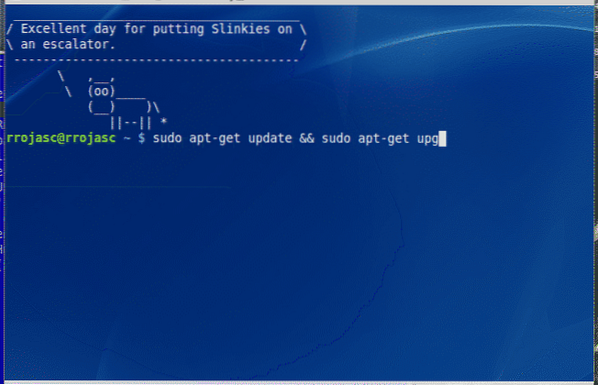
Om de tekenherkenning te verbeteren, moeten we veel opties en stappen volgen die in onze vorige tutorial werden beschreven: verwijderen van randen, verwijderen van ruis, optimalisatie van de grootte en paginarotatie, naast andere functies zoals bijsnijden.
Voor deze tutorial gebruiken we textcleaner, een script ontwikkeld door Fred's ImageMagick Scripts.
Download het script en voer het uit:
./textcleaner -g -e stretch -f 25 -o 10 -s 1Actualizar_GNULinux_Terminal_apt-get.gif-test.gif
Opmerking: geef het uitvoeringsmachtigingen voordat u het script uitvoert door "chmod +x textcleaner” als root of met sudo voorvoegsel.
Waar:
tekstopruimer: roept het programma op
-g: de afbeelding converteren naar grijswaarden
-e: enache
-f: filtergrootte
-zo: sharpamt, hoeveelheid pixelverscherping die moet worden toegepast op het resultaat.
Ga voor informatie en gebruiksvoorbeelden met textcleaner naar http://www.fmwconcepts.com/imagemagick/textcleaner/index.php
Zoals je ziet, heeft textcleaner de achtergrondkleur gewijzigd, waardoor het contrast tussen het lettertype en de achtergrond is vergroot.

Als we tesseract uitvoeren, zal het resultaat waarschijnlijk anders zijn:
tesseract-test.gif testoutput

Zoals je ziet is het resultaat echt verbeterd, zelfs als het niet helemaal nauwkeurig is.
Het bevel converteren geleverd door imagemagick stelt ons in staat om frames uit gif-afbeeldingen te extraheren om later door Tesseract te worden verwerkt, dit is handig als er extrabare inhoud is in verschillende frames van de gif-afbeelding.
De syntaxis is eenvoudig:
converterenHet resultaat wordt gegenereerd als aantal bestanden als frames in de gif, in het gegeven voorbeeld zouden de resultaten zijn: uitgang-0.jpg, uitgang-1.jpg, uitgang-2.jpg, enz.
Vervolgens kunt u ze verwerken met tesseract, waarbij u het instrueert om alle bestanden te verwerken met een jokerteken en het resultaat op te slaan in een enkel bestand door het volgende uit te voeren:
voor i in uitvoer-* ; doe tesseract $i outputresult; gedaan;Imagemagick heeft een enorme verscheidenheid aan opties om afbeeldingen te optimaliseren en er is geen generieke modus, voor elk soort scenario moet je de opdrachtmanpagina van convert lezen.
Ik hoop dat je deze tutorial over Tesseract nuttig vond.


