In dit artikel zullen we het basisgebruik van een groep per functie doornemen in panda's python. Alle opdrachten worden uitgevoerd op de Pycharm-editor.
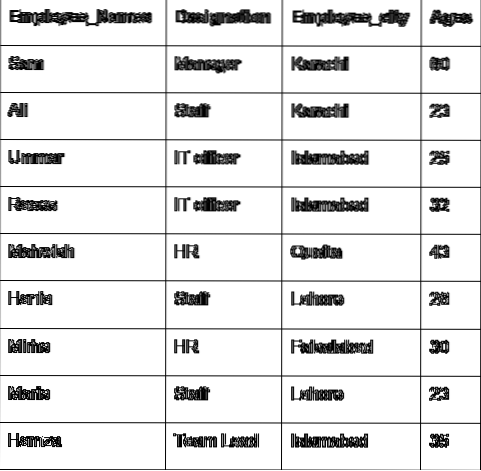
Laten we het hoofdconcept van de groep bespreken met behulp van de gegevens van de werknemer. We hebben een dataframe gemaakt met enkele nuttige werknemersgegevens (Employee_Names, Designation, Employee_city, Age).
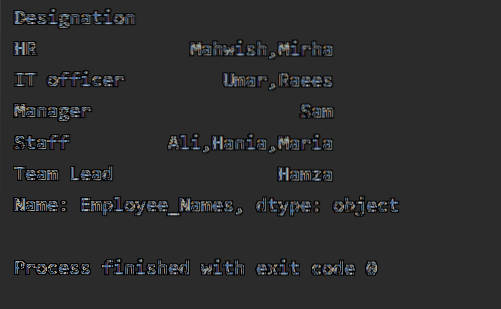
Tekenreeksaaneenschakeling met behulp van groeperen op functie
Met behulp van de groupby-functie kunt u tekenreeksen samenvoegen. Dezelfde records kunnen worden samengevoegd met ',' in een enkele cel.
Voorbeeld
In het volgende voorbeeld hebben we gegevens gesorteerd op basis van de kolom 'Aanduiding' van de werknemer en samengevoegd met de werknemers met dezelfde aanduiding. De lambda-functie wordt toegepast op 'Employees_Name'.
panda's importeren als pddf = pd.DataFrame(
'Employee_Names':['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Benoeming':['Manager', 'Personeel', 'IT-functionaris', 'IT-functionaris', 'HR', 'Staff', 'HR', 'Staff', 'Teamleider'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Leeftijd':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1=df.groupby("Aanduiding")['Medewerker_Namen'].apply(lambda Employee_Names: ','.join(Medewerkers_Namen))
afdrukken(df1)
Wanneer de bovenstaande code wordt uitgevoerd, wordt de volgende uitvoer weergegeven:
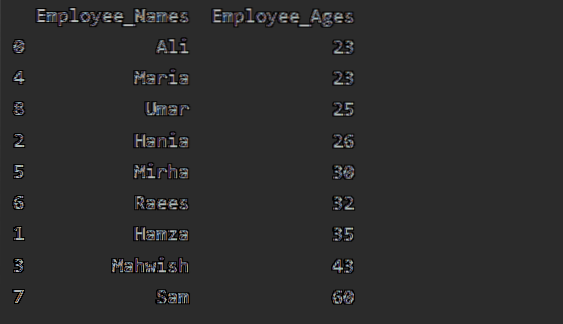
Waarden in oplopende volgorde sorteren
Gebruik het groupby-object in een regulier dataframe door '.to_frame()' en gebruik vervolgens reset_index() voor het opnieuw indexeren. Sorteer kolomwaarden door sort_values() aan te roepen.
Voorbeeld
In dit voorbeeld sorteren we de leeftijd van de werknemer in oplopende volgorde. Met behulp van het volgende stukje code hebben we de 'Employee_Age' in oplopende volgorde opgehaald met 'Employee_Names'.
panda's importeren als pddf = pd.DataFrame(
'Employee_Names':['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Benoeming':['Manager', 'Personeel', 'IT-functionaris', 'IT-functionaris', 'HR', 'Staff', 'HR', 'Staff', 'Teamleider'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Leeftijd':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1=df.groupby('Employee_Names')['Employee_Leeftijd'].som().naar_frame().reset_index().sort_values(by='Employee_Leeftijd')
afdrukken(df1)
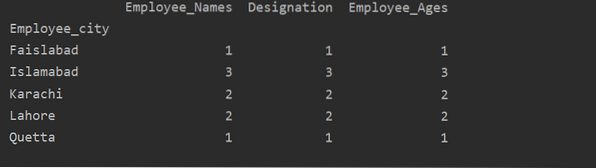
Gebruik van aggregaten met groupby
Er zijn een aantal functies of aggregaties beschikbaar die u kunt toepassen op gegevensgroepen zoals count(), sum(), mean(), median(), mode(), std(), min(), max().
Voorbeeld
In dit voorbeeld hebben we een functie 'count()' met groupby gebruikt om de werknemers te tellen die tot dezelfde 'Employee_city' behoren.
panda's importeren als pddf = pd.DataFrame(
'Employee_Names':['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Benoeming':['Manager', 'Personeel', 'IT-functionaris', 'IT-functionaris', 'HR', 'Staff', 'HR', 'Staff', 'Teamleider'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Leeftijd':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1=df.groupby('Werknemer_stad').tel()
afdrukken(df1)
Zoals u de volgende uitvoer kunt zien, tel onder de kolommen Benaming, Naam werknemer en Leeftijd werknemer nummers die bij dezelfde stad horen:
Gegevens visualiseren met groupby
Door gebruik te maken van de 'import matplotlib'.pyplot', kunt u uw gegevens in grafieken visualiseren.
Voorbeeld
Hier visualiseert het volgende voorbeeld de 'Employee_Age' met 'Employee_Nmaes' uit het gegeven DataFrame met behulp van de groupby-instructie.
panda's importeren als pdmatplotlib importeren.pyplot als plt
dataframe = pd.DataFrame(
'Employee_Names':['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Benoeming':['Manager', 'Personeel', 'IT-functionaris', 'IT-functionaris', 'HR', 'Staff', 'HR', 'Staff', 'Teamleider'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Leeftijd':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf()
dataframe.groupby('Medewerker_Namen').som().plot(kind='bar')
plt.tonen()
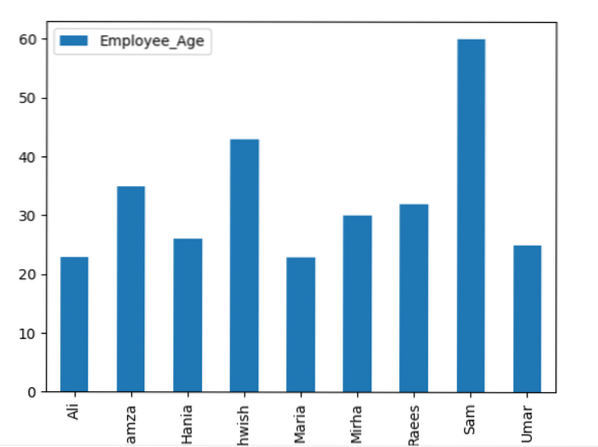
Voorbeeld
Om de gestapelde grafiek te plotten met groupby, draait u de 'stacked=true' en gebruikt u de volgende code:
panda's importeren als pdmatplotlib importeren.pyplot als plt
df = pd.DataFrame(
'Employee_Names':['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Benoeming':['Manager', 'Personeel', 'IT-functionaris', 'IT-functionaris', 'HR', 'Staff', 'HR', 'Staff', 'Teamleider'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Leeftijd':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby(['Employee_city','Employee_Names']).grootte().ontstapelen().plot(kind='bar',stacked=True, fontsize='6')
plt.tonen()
In de onderstaande grafiek is het aantal gestapelde werknemers dat tot dezelfde stad behoort.
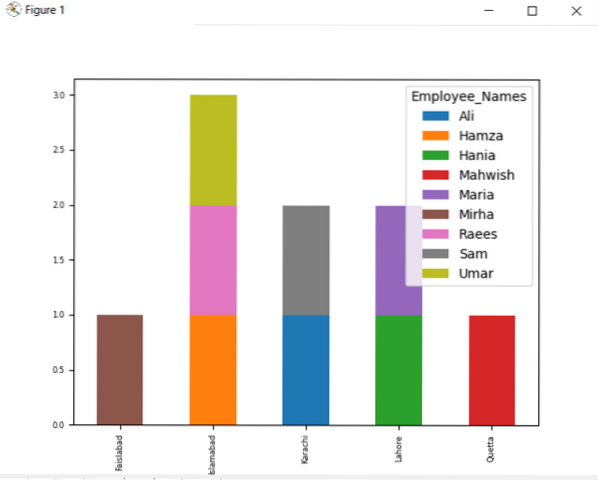
Kolomnaam wijzigen met de groep door
U kunt de geaggregeerde kolomnaam ook als volgt wijzigen met een nieuwe gewijzigde naam:
panda's importeren als pdmatplotlib importeren.pyplot als plt
df = pd.DataFrame(
'Employee_Names':['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Benoeming':['Manager', 'Personeel', 'IT-functionaris', 'IT-functionaris', 'HR', 'Staff', 'HR', 'Staff', 'Teamleider'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Leeftijd':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby('Employee_Names')['Aanduiding'].som().reset_index(name='Employee_Designation')
afdrukken(df1)
In het bovenstaande voorbeeld is de naam 'Aanduiding' gewijzigd in 'Employee_Designation'.
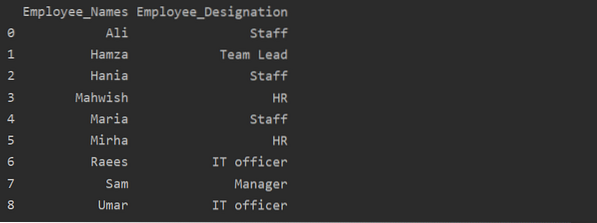
Groep op sleutel of waarde ophalen
Met behulp van de groupby-instructie kunt u vergelijkbare records of waarden uit het dataframe ophalen.
Voorbeeld
In het onderstaande voorbeeld hebben we groepsgegevens op basis van 'Aanduiding'. Vervolgens wordt de groep 'Personeel' opgehaald met behulp van de .getgroup('Personeel').
panda's importeren als pdmatplotlib importeren.pyplot als plt
df = pd.DataFrame(
'Employee_Names':['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Benoeming':['Manager', 'Personeel', 'IT-functionaris', 'IT-functionaris', 'HR', 'Staff', 'HR', 'Staff', 'Teamleider'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Leeftijd':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
extract_value = df.groupby('Aanduiding')
print(extract_value.get_group('Personeel'))
Het volgende resultaat wordt weergegeven in het uitvoervenster:

Waarde toevoegen aan groepslijst
Vergelijkbare gegevens kunnen worden weergegeven in de vorm van een lijst met behulp van de groupby-instructie. Groepeer eerst de gegevens op basis van een voorwaarde. Door de functie toe te passen, kunt u deze groep vervolgens eenvoudig in de lijsten plaatsen.
Voorbeeld
In dit voorbeeld hebben we vergelijkbare records in de groepslijst ingevoegd. Alle medewerkers worden ingedeeld in de groep op basis van 'Employee_city', en vervolgens door de functie 'Lambda' toe te passen, wordt deze groep opgehaald in de vorm van een lijst.
panda's importeren als pddf = pd.DataFrame(
'Employee_Names':['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Benoeming':['Manager', 'Personeel', 'IT-functionaris', 'IT-functionaris', 'HR', 'Staff', 'HR', 'Staff', 'Teamleider'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Leeftijd':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1=df.groupby('Employee_city')['Employee_Names'].toepassen (lambda group_series: group_series.tolist()).reset_index()
afdrukken(df1)
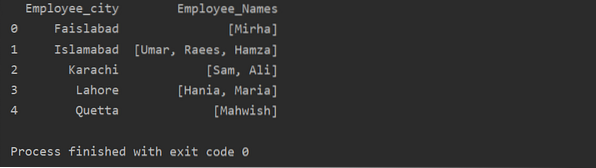
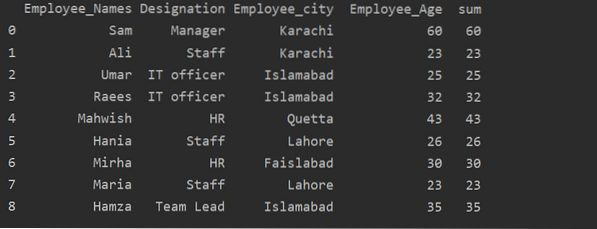
Gebruik van de functie Transformeren met groupby
De werknemers worden gegroepeerd volgens hun leeftijd, deze waarden bij elkaar opgeteld, en met behulp van de 'transform'-functie wordt een nieuwe kolom toegevoegd in de tabel:
panda's importeren als pddf = pd.DataFrame(
'Employee_Names':['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Benoeming':['Manager', 'Personeel', 'IT-functionaris', 'IT-functionaris', 'HR', 'Staff', 'HR', 'Staff', 'Teamleider'],
'Employee_city':['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Leeftijd':[60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df['som']=df.groupby(['Medewerker_Namen'])['Employee_Leeftijd'].transformeren('som')
afdrukken (df)
Conclusie
We hebben de verschillende toepassingen van groupby-statements in dit artikel onderzocht. We hebben laten zien hoe je de gegevens in groepen kunt verdelen, en door verschillende aggregaties of functies toe te passen, kun je deze groepen gemakkelijk terughalen.


