Dit is een vervolgartikel op het vorige. We zullen bespreken hoe u de zoekopdracht kunt verfijnen, complexere zoekcriteria met verschillende parameters kunt formuleren en de verschillende webformulieren van de Apache Solr-querypagina kunt begrijpen. We zullen ook bespreken hoe u het zoekresultaat kunt nabewerken met behulp van verschillende uitvoerformaten zoals XML, CSV en JSON.
Apache Solr opvragen
Apache Solr is ontworpen als een webtoepassing en service die op de achtergrond draait. Het resultaat is dat elke clienttoepassing met Solr kan communiceren door er query's naar te sturen (de focus van dit artikel), de documentkern te manipuleren door geïndexeerde gegevens toe te voegen, bij te werken en te verwijderen, en kerngegevens te optimaliseren. Er zijn twee opties - via dashboard/webinterface of met behulp van een API door een bijbehorend verzoek te verzenden.
Het is gebruikelijk om de eerste optie voor testdoeleinden en niet voor reguliere toegang. De onderstaande afbeelding toont het Dashboard van de Apache Solr Administration User Interface met de verschillende queryformulieren in de webbrowser Firefox.
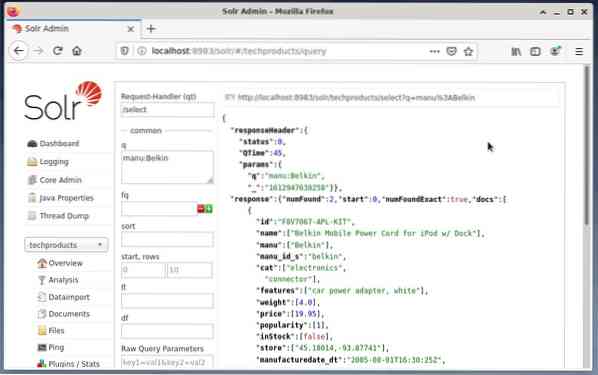
Kies eerst in het menu onder het kernselectieveld het menu-item "Query". Vervolgens toont het dashboard verschillende invoervelden als volgt:
- Verzoekbehandelaar (qt):
Bepaal welk soort verzoek u naar Solr . wilt sturen. U kunt kiezen tussen de standaard verzoekhandlers "/select" (geïndexeerde gegevens opvragen), "/update" (geïndexeerde gegevens bijwerken) en "/delete" (de gespecificeerde geïndexeerde gegevens verwijderen), of een zelfgedefinieerde. - Vraaggebeurtenis (q):
Definieer welke veldnamen en waarden moeten worden geselecteerd. - Zoekopdrachten filteren (fq):
Beperk de superset van documenten die kunnen worden geretourneerd zonder de documentscore te beïnvloeden. - Sorteervolgorde (sorteren):
Definieer de sorteervolgorde van de queryresultaten in oplopend of aflopend - Uitvoervenster (start en rijen):
Beperk de uitvoer tot de gespecificeerde elementen - Veldlijst (fl):
Beperkt de informatie in een vraagantwoord tot een gespecificeerde lijst met velden. - Uitvoerformaat (wt):
Definieer het gewenste uitvoerformaat. De standaardwaarde is JSON.
Als u op de knop Query uitvoeren klikt, wordt het gewenste verzoek uitgevoerd. Kijk hieronder voor praktische voorbeelden.
als de tweede optie, u kunt een verzoek verzenden met behulp van een API. Dit is een HTTP-verzoek dat door elke toepassing naar Apache Solr kan worden verzonden. Solr verwerkt het verzoek en retourneert een antwoord. Een speciaal geval hiervan is verbinding maken met Apache Solr via Java API. Dit is uitbesteed aan een apart project genaamd SolrJ [7] - een Java API zonder dat een HTTP-verbinding nodig is.
Querysyntaxis
De querysyntaxis wordt het best beschreven in [3] en [5]. De verschillende parameternamen komen direct overeen met de namen van de invoervelden in de hierboven toegelichte formulieren. In de onderstaande tabel staan ze vermeld, plus praktische voorbeelden.
Index van queryparameters
| Parameter | Omschrijving | Voorbeeld |
|---|---|---|
| q | De belangrijkste queryparameter van Apache Solr - de veldnamen en waarden. Hun overeenkomstscores documenteren naar termen in deze parameter. | ID:5 auto's:*adilla* *:X5 |
| fq | Beperk de resultaatset tot de superset-documenten die overeenkomen met het filter, bijvoorbeeld gedefinieerd via Function Range Query Parser | model- id,model |
| begin | Offsets voor paginaresultaten (begin). De standaardwaarde van deze parameter is 0. | 5 |
| rijen | Offsets voor paginaresultaten (einde). De waarde van deze parameter is standaard 10 | 15 |
| soort | Het specificeert de lijst met velden gescheiden door komma's, op basis waarvan de queryresultaten moeten worden gesorteerd | model asc |
| fl | Het specificeert de lijst met velden die moeten worden geretourneerd voor alle documenten in de resultatenset | model- id,model |
| wt | Deze parameter vertegenwoordigt het type antwoordschrijver waarvan we het resultaat wilden bekijken. De waarde hiervan is standaard JSON. | json xml |
Zoekopdrachten worden uitgevoerd via HTTP GET-verzoek met de queryreeks in de q-parameter. Onderstaande voorbeelden zullen verduidelijken hoe dit werkt. In gebruik is curl om de query naar Solr te sturen die lokaal is geïnstalleerd.
- Haal alle datasets op uit de core auto's curl http://localhost:8983/solr/cars/query?q=*:*
- Haal alle datasets op uit de kernauto's met een id van 5 curl http://localhost:8983/solr/cars/query?q=id:5
- Haal het veldmodel op uit alle datasets van de kernauto's
Optie 1 (met escaped &): curl http://localhost:8983/solr/cars/query?q=id:*\&fl=modelOptie 2 (zoekopdracht in enkele vinkjes):
curl 'http://localhost:8983/solr/cars/query'?q=id:*&fl=model' - Haal alle datasets van de kernauto's op, gesorteerd op prijs in aflopende volgorde, en voer alleen de velden merk, model en prijs uit (versie in enkele vinkjes): curl http://localhost:8983/solr/cars/query -d '
q=*:*&
sort=prijs desc&
fl=merk,model,prijs ' - Haal de eerste vijf datasets van de kernauto's op, gesorteerd op prijs in aflopende volgorde, en voer alleen de velden merk, model en prijs uit (versie in enkele vinkjes): curl http://localhost:8983/solr/cars/query - d'
q=*:*&
rijen=5&
sort=prijs desc&
fl=merk,model,prijs ' - Haal de eerste vijf datasets van de kernauto's op, gesorteerd op prijs in aflopende volgorde, en voer de velden merk, model en prijs plus de relevantiescore uit, alleen (versie in enkele vinkjes): curl http://localhost:8983/solr/ auto's/query -d '
q=*:*&
rijen=5&
sort=prijs desc&
fl=merk,model,prijs,score ' - Retourneer alle opgeslagen velden evenals de relevantiescore: curl http://localhost:8983/solr/cars/query -d '
q=*:*&
fl=*,score '
Bovendien kunt u uw eigen verzoekhandler definiëren om de optionele verzoekparameters naar de queryparser te sturen om te bepalen welke informatie wordt geretourneerd.
Queryparsers
Apache Solr gebruikt een zogenaamde query-parser - een component die uw zoekstring vertaalt naar specifieke instructies voor de zoekmachine. Een query-parser staat tussen u en het document waarnaar u zoekt.
Solr wordt geleverd met een verscheidenheid aan parsertypen die verschillen in de manier waarop een ingediende query wordt afgehandeld. De Standard Query Parser werkt goed voor gestructureerde query's, maar is minder tolerant voor syntaxisfouten. Tegelijkertijd zijn zowel de DisMax als de Extended DisMax Query Parser geoptimaliseerd voor natuurlijke taalachtige zoekopdrachten. Ze zijn ontworpen om eenvoudige woordgroepen die door gebruikers zijn ingevoerd te verwerken en om te zoeken naar afzonderlijke termen in verschillende velden met verschillende wegingen.
Verder biedt Solr ook zogenaamde Function Queries waarmee een functie kan worden gecombineerd met een query om een specifieke relevantiescore te genereren. Deze parsers heten Function Query Parser en Function Range Query Parser. Het onderstaande voorbeeld toont de laatste om alle gegevenssets voor "bmw" (opgeslagen in het gegevensveld make) te kiezen met de modellen van 318 tot 323:
curl http://localhost:8983/solr/cars/query -d 'q=merk:bmw&
fq=model:[318 TOT 323] '
Nabewerking van resultaten
Het verzenden van zoekopdrachten naar Apache Solr is een deel, maar het zoekresultaat van het andere nabewerken. Ten eerste kunt u kiezen tussen verschillende antwoordformaten - van JSON tot XML, CSV en een vereenvoudigd Ruby-formaat. Geef eenvoudig de bijbehorende wt-parameter op in een query. Het onderstaande codevoorbeeld laat dit zien voor het ophalen van de dataset in CSV-indeling voor alle items die curl gebruiken met escaped &:
curl http://localhost:8983/solr/cars/query?q=id:5\&wt=csvDe uitvoer is als volgt een door komma's gescheiden lijst:

Om het resultaat als XML-gegevens te ontvangen, maar alleen de twee uitvoervelden maken en model, voert u de volgende query uit:
curl http://localhost:8983/solr/cars/query?q=*:*\&fl=merk,model\&wt=xmlDe uitvoer is anders en bevat zowel de antwoordheader als het daadwerkelijke antwoord:
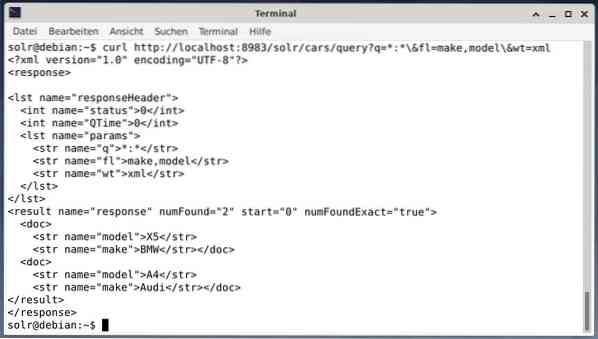
Wget drukt eenvoudig de ontvangen gegevens af op stdout. Hierdoor kunt u het antwoord nabewerken met behulp van standaard opdrachtregelprogramma's. Om er een paar te noemen, dit bevat jq [9] voor JSON, xsltproc, xidel, xmlstarlet [10] voor XML en csvkit [11] voor CSV-formaat.
Conclusie
Dit artikel toont verschillende manieren om zoekopdrachten naar Apache Solr te sturen en legt uit hoe u het zoekresultaat kunt verwerken. In het volgende deel leert u hoe u Apache Solr gebruikt om te zoeken in PostgreSQL, een relationeel databasebeheersysteem.
Over de Auteurs
Jacqui Kabeta is een milieuactivist, fervent onderzoeker, trainer en mentor. In verschillende Afrikaanse landen heeft ze gewerkt in de IT-industrie en NGO-omgevingen.
Frank Hofmann is een IT-ontwikkelaar, trainer en auteur en werkt het liefst vanuit Berlijn, Genève en Kaapstad. Co-auteur van het Debian Package Management Book verkrijgbaar bij dpmb.org
Links en referenties
- [1] Apache Solr, https://lucene.apache.org/solr/
- [2] Frank Hofmann en Jacqui Kabeta: Inleiding tot Apache Solr. Deel 1, http://linuxhint.com
- [3] Yonik Seelay: Solr Query-syntaxis, http://yonik.com/solr/query-syntaxis/
- [4] Yonik Seelay: Solr-zelfstudie, http://yonik.com/solr-tutorial/
- [5] Apache Solr: gegevens opvragen, Tutorialspoint, https://www.zelfstudiepunt.com/apache_solr/apache_solr_querying_data.htm
- [6] Lucene, https://lucene.apache.org/
- [7] SolrJ, https://lucene.apache.org/solr/guide/8_8/using-solrj.html
- [8] krul, https://curl.zie/
- [9] jq, https://github.com/stedolan/jq
- [10] xmlstarlet, http://xmlstar.bronvervalsing.netto/
- [11] csvkit, https://csvkit.leesdedocs.io/nl/laatste/


