Waarom is Lucene nodig??
Zoeken is een van de meest voorkomende bewerkingen die we meerdere keren per dag uitvoeren. Deze zoekopdracht kan plaatsvinden op meerdere webpagina's die bestaan op het web of een muziektoepassing of een coderepository of een combinatie van al deze. Je zou kunnen denken dat een eenvoudige relationele database ook het zoeken kan ondersteunen. Dit is correct. Databases zoals MySQL ondersteunen zoeken in volledige tekst. Maar hoe zit het met het web of een muziektoepassing of een coderepository of een combinatie van al deze?? De database kan deze gegevens niet in de kolommen opslaan. Zelfs als dat zo is, zal het onaanvaardbaar veel tijd kosten om de zoekopdracht zo groot uit te voeren.
Een full-text zoekmachine kan een zoekopdracht uitvoeren op miljoenen bestanden tegelijk. De snelheid waarmee gegevens tegenwoordig in een applicatie worden opgeslagen, is enorm. Zoeken in volledige tekst op dit soort gegevensvolumes is een moeilijke taak. Dit komt omdat de informatie die we nodig hebben mogelijk in een enkel bestand bestaat uit miljarden bestanden die op internet worden bewaard.
Hoe Lucene werkt?
De voor de hand liggende vraag die bij u opkomt, is hoe Lucene zo snel is in het uitvoeren van zoekopdrachten in volledige tekst?? Het antwoord hierop is natuurlijk met behulp van indices die het creëert. Maar in plaats van een klassieke index te maken, maakt Lucene gebruik van Omgekeerde indices.
In een klassieke index verzamelen we voor elk document de volledige lijst met woorden of termen die het document bevat. In een geïnverteerde index slaan we voor elk woord in alle documenten op welk document en welke positie dit woord/de term kan worden gevonden op. Dit is een algoritme van hoge kwaliteit dat het zoeken heel gemakkelijk maakt. Bekijk het volgende voorbeeld van het maken van een klassieke index:
Doc1 -> "Dit", "is", "eenvoudig", "Lucene", "voorbeeld", "klassiek", "omgekeerd", "index"Doc2 -> "Running", "Elasticsearch", "Ubuntu", "Update"
Doc3 -> "RabbitMQ", "Lucene", "Kafka", "", "Spring", "Boot"
Als we een omgekeerde index gebruiken, hebben we indices zoals:
Dit -> (2, 71)Luceen -> (1, 9), (12,87)
Apache -> (12, 91)
Kader -> (32, 11)
Omgekeerde indices zijn veel gemakkelijker te onderhouden. Stel dat als we Apache willen vinden in mijn termen, ik meteen antwoorden heb met omgekeerde indices, terwijl klassiek zoeken op volledige documenten draait die misschien niet mogelijk waren in realtime scenario's.
Lucene-workflow
Voordat Lucene de gegevens daadwerkelijk kan doorzoeken, moet het stappen uitvoeren. Laten we deze stappen visualiseren voor een beter begrip:
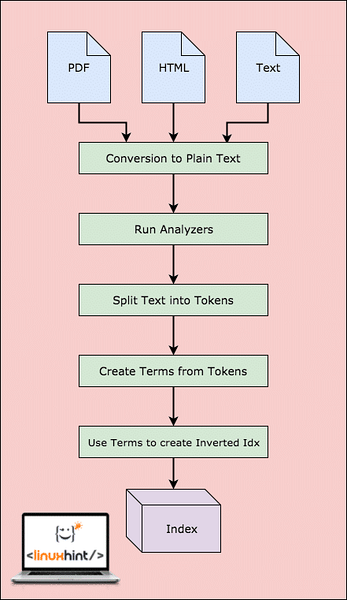
Lucene-workflow
Zoals in het diagram te zien is, gebeurt dit in Lucene:
- Lucene krijgt de documenten en andere gegevensbronnen binnen
- Voor elk document converteert Lucene deze gegevens eerst naar platte tekst en vervolgens converteert de Analyzers deze bron naar platte tekst
- Voor elke term in de platte tekst worden de geïnverteerde indices gemaakt
- De indexen zijn klaar om doorzocht te worden
Met deze workflow is Lucene een zeer sterke full-text zoekmachine. Maar dit is het enige deel dat Lucene vervult. We moeten het werk zelf doen. Laten we eens kijken naar de componenten van Indexing die nodig zijn.
Lucene-componenten
In deze sectie beschrijven we de basiscomponenten en de basisklassen van Lucene die worden gebruikt om indices te maken:
- Directory's: Een Lucene-index slaat gegevens op in normale bestandssysteemmappen of in het geheugen als u meer prestaties nodig hebt. Het is volledig de keuze van de app om gegevens op te slaan waar het maar wil, een database, het RAM-geheugen of de schijf.
- Documenten: De gegevens die we naar de Lucene-engine voeren, moeten worden geconverteerd naar platte tekst. Om dit te doen, maken we een Document-object dat die gegevensbron vertegenwoordigt. Als we later een zoekopdracht uitvoeren, krijgen we als resultaat een lijst met documentobjecten die voldoen aan de zoekopdracht die we hebben doorstaan.
- Velden: Documenten worden gevuld met een verzameling velden. Een veld is gewoon een paar (naam, waarde) artikelen. Dus terwijl we een nieuw documentobject maken, moeten we het vullen met dat soort gekoppelde gegevens. Wanneer een veld omgekeerd geïndexeerd is, wordt de waarde van het veld getokeniseerd en kan het worden doorzocht. Nu, terwijl we velden gebruiken, is het niet belangrijk om het werkelijke paar op te slaan, maar alleen het geïnverteerde geïndexeerde. Op deze manier kunnen we beslissen welke gegevens alleen doorzoekbaar zijn en niet belangrijk om te worden opgeslagen. Laten we hier een voorbeeld bekijken:

Veldindexering
In bovenstaande tabel hebben we besloten om sommige velden op te slaan en andere niet. Het body-veld wordt niet opgeslagen maar geïndexeerd. Dit betekent dat de e-mail als resultaat wordt geretourneerd wanneer de query voor een van de voorwaarden voor de hoofdinhoud wordt uitgevoerd.
- voorwaarden: Termen vertegenwoordigt een woord uit de tekst. Termen worden geëxtraheerd uit de analyse en tokenisatie van de waarden van Fields, dus Term is de kleinste eenheid waarop de zoekopdracht wordt uitgevoerd.
- analysatoren: Een analysator is het meest cruciale onderdeel van het indexerings- en zoekproces. Het is de Analyzer die de platte tekst omzet in tokens en termen zodat ze kunnen worden doorzocht. Nou, dat is niet de enige verantwoordelijkheid van een analysator. Een analysator gebruikt een tokenizer om tokens te maken. Een analysator voert ook de volgende taken uit:
- Stemming: een analysator zet het woord om in een stam. Dit betekent dat 'bloemen' wordt omgezet naar het stamwoord 'bloem'. Dus wanneer een zoekopdracht naar 'bloem' wordt uitgevoerd, wordt het document geretourneerd.
- Filteren: Een Analyzer filtert ook de stopwoorden zoals 'The', 'is' etc. omdat deze woorden geen zoekopdrachten aantrekken om uit te voeren en niet productief zijn.
- Normalisatie: dit proces verwijdert accenten en andere tekenmarkeringen.
Dit is gewoon de normale verantwoordelijkheid van StandardAnalyzer.
Voorbeeldtoepassing:
We zullen een van de vele Maven-archetypen gebruiken om een voorbeeldproject voor ons voorbeeld te maken. Om het project aan te maken, voert u de volgende opdracht uit in een map die u als werkruimte gaat gebruiken:
mvn archetype:generate -DgroupId=com.linuxhint.voorbeeld -DartifactId=LH-LuceneExample -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=falseAls u maven voor de eerste keer gebruikt, duurt het enkele seconden om de opdracht Genereer uit te voeren, omdat maven alle vereiste plug-ins en artefacten moet downloaden om de generatietaak uit te voeren. Zo ziet de projectuitvoer eruit:
Projectconfiguratie
Nadat u het project hebt gemaakt, kunt u het openen in uw favoriete IDE. De volgende stap is het toevoegen van de juiste Maven-afhankelijkheden aan het project. Hier is de pom.xml-bestand met de juiste afhankelijkheden:
Ten slotte, om alle JAR's te begrijpen die aan het project zijn toegevoegd toen we deze afhankelijkheid toevoegden, kunnen we een eenvoudige Maven-opdracht uitvoeren waarmee we een volledige Dependency Tree voor een project kunnen zien wanneer we er enkele afhankelijkheden aan toevoegen. Hier is een commando dat we kunnen gebruiken:
mvn-afhankelijkheid:boomWanneer we deze opdracht uitvoeren, wordt de volgende afhankelijkheidsstructuur weergegeven: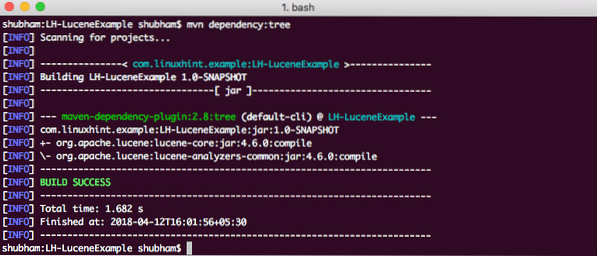
Ten slotte maken we een SimpleIndexer-klasse die wordt uitgevoerd
java importeren.io.Het dossier;
java importeren.io.Bestandslezer;
java importeren.io.IOUitzondering;
import organisatie.apache.luceen.analyse.analysator;
import organisatie.apache.luceen.analyse.standaard-.StandaardAnalyse;
import organisatie.apache.luceen.document.Document;
import organisatie.apache.luceen.document.Opgeslagen veld;
import organisatie.apache.luceen.document.TekstVeld;
import organisatie.apache.luceen.inhoudsopgave.Indexschrijver;
import organisatie.apache.luceen.inhoudsopgave.IndexWriterConfig;
import organisatie.apache.luceen.winkel.FSDirectory;
import organisatie.apache.luceen.gebruik.Versie;
openbare klasse SimpleIndexer
private static final String indexDirectory = "/Users/shubham/somewhere/LH-LuceneExample/Index";
private static final String dirToBeIndexed = "/Users/shubham/somewhere/LH-LuceneExample/src/main/java/com/linuxhint/example";
public static void main(String[] args) gooit Exception
Bestand indexDir = nieuw bestand (indexDirectory);
Bestand dataDir = nieuw bestand (dirToBeIndexed);
SimpleIndexer indexer = nieuwe SimpleIndexer();
int numIndexed = indexer.index (indexDir, dataDir);
Systeem.uit.println("Totaal geïndexeerde bestanden" + numIndexed);
private int index (File indexDir, File dataDir) gooit IOException
Analyzer-analysator = nieuwe StandardAnalyzer (versie.LUCENE_46);
IndexWriterConfig config = nieuwe IndexWriterConfig (versie.LUCENE_46,
analysator);
IndexWriter indexWriter = nieuwe IndexWriter(FSDirectory.open(indexDir),
configuratie);
Bestand[] bestanden = dataDir.lijstBestanden();
for (Bestand f: bestanden)
Systeem.uit.println("Indexeringsbestand" + f.getCanonicalPath());
Document doc = nieuw document();
doc.add(new TextField("content", new FileReader(f)));
doc.add(new StoredField("fileName", f.getCanonicalPath()));
indexWriter.addDocument(doc);
int numIndexed = indexWriter.maxDoc();
indexWriter.dichtbij();
retour numIndexed;
In deze code hebben we zojuist een documentinstantie gemaakt en een nieuw veld toegevoegd dat de bestandsinhoud vertegenwoordigt. Dit is de uitvoer die we krijgen als we dit bestand uitvoeren:
Indexeringsbestand /Users/shubham/somewhere/LH-LuceneExample/src/main/java/com/linuxhint/example/SimpleIndexer.JavaTotaal aantal geïndexeerde bestanden 1
Er wordt ook een nieuwe map binnen het project gemaakt met de volgende inhoud:
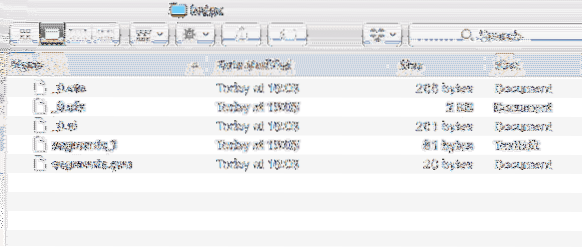
Indexgegevens
We zullen analyseren welke bestanden in deze Index zijn gemaakt in meer lessen over Lucene.
Conclusie
In deze les hebben we gekeken naar hoe Apache Lucene werkt en hebben we ook een eenvoudige voorbeeldtoepassing gemaakt die was gebaseerd op Maven en java.


