Om het concept van zoeken in volledige tekst te begrijpen, moet u de kennis van patroonzoeken onthouden via het LIKE-trefwoord. Laten we dus aannemen dat een tabel 'persoon' in de database 'test' de volgende records bevat:.
>> SELECTEER * VAN persoon;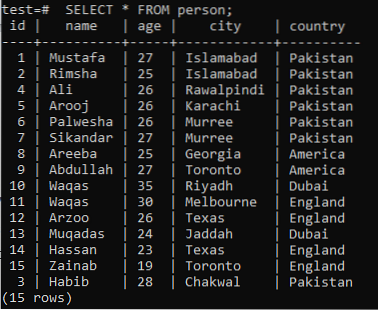
Laten we aannemen dat u de records van deze tabel wilt ophalen, waarbij de kolom 'naam' een teken 'i' heeft in een van zijn waarden. Probeer de onderstaande SELECT-query terwijl u de LIKE-component in de opdrachtshell gebruikt:. Uit de onderstaande uitvoer kunt u zien dat we slechts 5 records hebben voor dit specifieke personage 'i' in de kolom 'naam'.
>> SELECTEER * VAN persoon WAAR naam LIKE '%i%';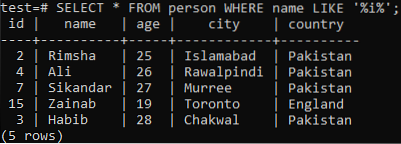
Gebruik van tv-sector:
Soms heeft het geen zin om het LIKE-sleutelwoord te gebruiken om snel een patroon te zoeken, hoewel het woord er wel is. Misschien zou je overwegen om standaard expressies te gebruiken, en hoewel dit een haalbaar alternatief is, zijn reguliere expressies zowel sterk als traag. Het hebben van een procedurele vector voor hele woorden in een tekst, een lokale beschrijving van die woorden, is een veel efficiëntere manier om dit probleem aan te pakken. Het concept van volledig zoeken naar tekst en het gegevenstype tsvector is gemaakt om hierop te reageren. Er zijn twee methoden in PostgreSQL die precies doen wat we willen:
- Naar_tvsector: Gebruikt om een lijst met tokens te maken (ts betekent voor "tekst zoeken").
- Naar_tsquery: Wordt gebruikt om de vector te doorzoeken op incidenties van specifieke termen of zinsdelen.
Voorbeeld 01:
Laten we beginnen met een eenvoudige illustratie van het maken van een vector. Stel dat je een vector voor het touwtje wilt maken: "Sommige mensen hebben krullend bruin haar door goed te borstelen".”. Dus je moet een functie to_tvsector() schrijven samen met deze zin tussen haakjes van een SELECT-query zoals hieronder toegevoegd. Uit de onderstaande uitvoer kun je zien dat het een vector van verwijzingen (bestandsposities) voor elk token zou opleveren, en ook waar termen met weinig context, zoals artikelen (de) en voegwoorden (en, of), opzettelijk worden genegeerd.
>> SELECT to_tsvector('Sommige mensen hebben krullende bruine haren door goed te borstelen');
Voorbeeld 02:
Stel dat je twee documenten hebt met in beide wat gegevens. Om deze gegevens op te slaan, gebruiken we nu een echt voorbeeld van het genereren van tokens. Stel dat u een tabel 'Data' hebt gemaakt in uw database 'test' met enkele kolommen erin met behulp van de onderstaande CREATE TABLE-query. Vergeet niet om er een TVSECTOR-type kolom met de naam 'token' in te maken. In de onderstaande uitvoer kun je de tabel bekijken die is gemaakt.
>> CREATE TABEL Gegevens (Id SERILE PRIMAIRE SLEUTEL, info TEXT, token TSVECTOR);
Nu is het aan ons om de algemene gegevens van beide documenten in deze tabel toe te voegen. Dus probeer de onderstaande INSERT-opdracht in uw opdrachtregelshell om dit te doen. Ten slotte zijn de records van beide documenten met succes toegevoegd aan de tabel 'Data'.
>> INSERT INTO Data (info) VALUES ('Twee fouten kunnen er nooit één goed maken'.'), ('Hij is degene die kan voetballen'.'), ('Kan ik hier een rol in spelen?'?'), ('De pijn van binnen is niet te begrijpen'), ('Breng perzik in je leven);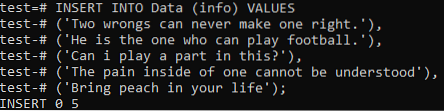
Nu moet je de tokenkolom van beide documenten koloniseren met hun specifieke vector. Uiteindelijk zal een eenvoudige UPDATE-query de tokenskolom vullen met de bijbehorende vector voor elk bestand. U moet dus de onderstaande query uitvoeren in de opdrachtshell om dit te doen. De uitvoer laat zien dat de update eindelijk is uitgevoerd.
>> UPDATE Gegevens f1 SET token = to_tsvector(f1.info) VANUIT Gegevens f2;
Nu we alles op zijn plaats hebben, keren we terug naar onze illustratie van "kan een" met een scan. To_tsquery met de AND-operator, zoals eerder gezegd, maakt geen verschil tussen de locaties van de bestanden in de bestanden, zoals blijkt uit de onderstaande uitvoer.
>> SELECT Id, info FROM Data WHERE token @@ to_tsquery('can & one');
Voorbeeld 04:
Om woorden te vinden die "naast" elkaar staan, zullen we dezelfde zoekopdracht proberen met de '<->'operator'. De wijziging wordt weergegeven in de onderstaande uitvoer:.
>> SELECT Id, info FROM Data WHERE token @@ to_tsquery('can <-> een');
Hier is een voorbeeld van geen direct woord naast een ander.
>> SELECT Id, info FROM Data WHERE token @@ to_tsquery('one <-> pijn');
Voorbeeld 05:
We zullen de woorden vinden die niet direct naast elkaar staan door een getal in de afstandsoperator te gebruiken om naar afstand te verwijzen. De nabijheid tussen 'breng' en 'leven is 4 woorden, afgezien van de weergegeven afbeelding.
>> SELECT * FROM Data WHERE token @@ to_tsquery('bring <4> leven');
Om de nabijheid tussen de woorden voor bijna 5 woorden te controleren, is hieronder toegevoegd:.
>> SELECT * FROM Data WHERE token @@ to_tsquery('wrong <5> Rechtsaf');
Conclusie:
Ten slotte heb je alle eenvoudige en gecompliceerde voorbeelden van zoeken in volledige tekst gedaan met behulp van de operatoren en functies To_tvsector en to_tsquery.


