PyTorch heeft weinig grote voordelen als rekenpakket, zoals:
- Het is mogelijk om rekengrafieken te bouwen terwijl we bezig zijn. Dit betekent dat het niet nodig is om vooraf te weten wat de geheugenvereisten van de grafiek zijn. We kunnen vrijelijk een neuraal netwerk maken en het tijdens runtime evalueren.
- Easy to Python API die gemakkelijk kan worden geïntegreerd
- Ondersteund door Facebook, dus de community-ondersteuning is erg sterk
- Biedt native ondersteuning voor meerdere GPU's
PyTorch wordt voornamelijk omarmd door de Data Science-gemeenschap vanwege het vermogen om neurale netwerken gemakkelijk te definiëren. Laten we dit rekenpakket in actie zien in deze les.
PyTorch installeren
Even een opmerking voordat je begint, je kunt voor deze les een virtuele omgeving gebruiken die we kunnen maken met het volgende commando:
python -m virtualenv pytorchbron pytorch/bin/activate
Zodra de virtuele omgeving actief is, kunt u de PyTorch-bibliotheek in de virtuele omgeving installeren, zodat de voorbeelden die we vervolgens maken, kunnen worden uitgevoerd:
pip installeer pytorchWe zullen in deze les gebruik maken van Anaconda en Jupyter. Als je het op je computer wilt installeren, kijk dan naar de les die beschrijft "Hoe Anaconda Python op Ubuntu 18 te installeren".04 LTS" en deel uw feedback als u problemen ondervindt. Om PyTorch met Anaconda te installeren, gebruikt u de volgende opdracht in de terminal van Anaconda:
conda install -c pytorch pytorchWe zien zoiets als dit wanneer we het bovenstaande commando uitvoeren:
Zodra alle benodigde pakketten zijn geïnstalleerd en klaar zijn, kunnen we aan de slag met het gebruik van de PyTorch-bibliotheek met de volgende importinstructie:
fakkel importerenLaten we beginnen met standaard PyTorch-voorbeelden nu we de vereiste pakketten hebben geïnstalleerd.
Aan de slag met PyTorch
Omdat we weten dat neurale netwerken fundamenteel kunnen worden gestructureerd omdat Tensors en PyTorch rond tensors zijn gebouwd, is er meestal een aanzienlijke prestatieverbetering. We gaan aan de slag met PyTorch door eerst het type Tensors te onderzoeken dat het biedt. Om hiermee aan de slag te gaan, importeert u de benodigde pakketten:
fakkel importerenVervolgens kunnen we een niet-geïnitialiseerde Tensor definiëren met een gedefinieerde grootte:
x = fakkel.leeg(4, 4)print("Arraytype: ".formaat(x.type)) # type
print("Arrayvorm: ".formaat(x.vorm)) # vorm
afdrukken(x)
We zien zoiets als dit wanneer we het bovenstaande script uitvoeren:
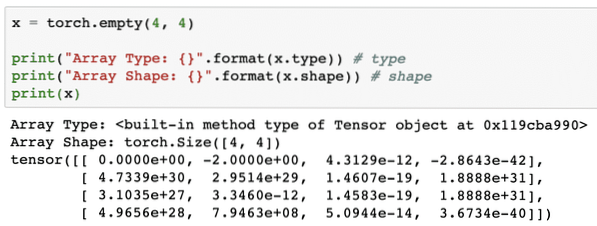
We hebben zojuist een niet-geïnitialiseerde Tensor gemaakt met een gedefinieerde grootte in het bovenstaande script. Om te herhalen van onze Tensorflow-les, tensoren kunnen worden aangeduid als n-dimensionale array waarmee we gegevens in complexe dimensies kunnen weergeven.
Laten we nog een voorbeeld uitvoeren waarbij we een Torched-tensor initialiseren met willekeurige waarden:
random_tensor = fakkel.rand(5, 4)print(willekeurige_tensor)
Wanneer we de bovenstaande code uitvoeren, zien we een willekeurig tensor-object afgedrukt:
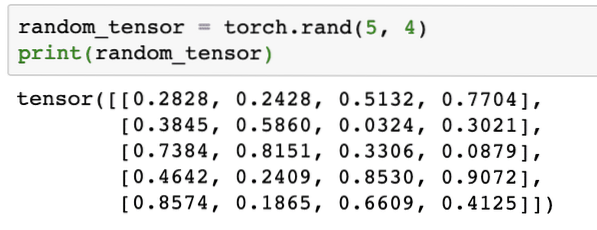
Houd er rekening mee dat de uitvoer voor bovenstaande willekeurige Tensor voor u anders kan zijn, omdat het willekeurig is !
Conversie tussen NumPy en PyTorch
NumPy en PyTorch zijn volledig compatibel met elkaar. Daarom is het gemakkelijk om NumPy-arrays om te zetten in tensoren en omgekeerd. Afgezien van het gemak dat API biedt, is het waarschijnlijk gemakkelijker om de tensors te visualiseren in de vorm van NumPy-arrays in plaats van Tensors, of noem het gewoon mijn liefde voor NumPy!
We zullen bijvoorbeeld NumPy in ons script importeren en een eenvoudige willekeurige array definiëren:
importeer numpy als nparray = np.willekeurig.rand(4, 3)
transformeerde_tensor = fakkel.from_numpy(array)
print("\n".formaat (getransformeerde_tensor))
Wanneer we de bovenstaande code uitvoeren, zien we het getransformeerde tensorobject afgedrukt:
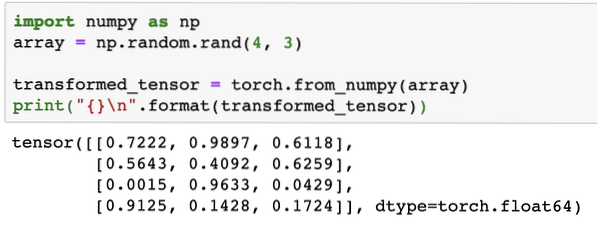
Laten we nu proberen deze tensor terug te converteren naar een NumPy-array:
numpy_arr = getransformeerde_tensor.numpy()print(" \n".formaat(type(numpy_arr), numpy_arr))
Wanneer we de bovenstaande code uitvoeren, zien we de getransformeerde NumPy-array afgedrukt:
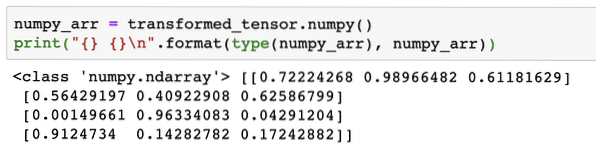
Als we goed kijken, blijft zelfs de precisie van de conversie behouden tijdens het converteren van de array naar een tensor en het vervolgens terug converteren naar een NumPy-array.
Tensorbewerkingen
Voordat we onze discussie over neurale netwerken beginnen, moeten we de bewerkingen kennen die op Tensors kunnen worden uitgevoerd tijdens het trainen van neurale netwerken. We zullen ook uitgebreid gebruik maken van de NumPy-module.
Een tensor snijden
We hebben al gekeken hoe we een nieuwe Tensor kunnen maken, laten we er nu een maken en plak het:
vector = fakkel.tensor([1, 2, 3, 4, 5, 6])afdrukken(vector[1:4])
Bovenstaand codefragment geeft ons de volgende uitvoer:
tensor([2, 3, 4])We kunnen de laatste index negeren:
afdrukken(vector[1:])En we zullen ook terugkrijgen wat er wordt verwacht met een Python-lijst:
tensor([2, 3, 4, 5, 6])Een zwevende tensor maken
Laten we nu een zwevende tensor maken:
float_vector = fakkel.FloatTensor([1, 2, 3, 4, 5, 6])print(float_vector)
Bovenstaand codefragment geeft ons de volgende uitvoer:
tensor([1., 2., 3., 4., 5., 6.])Type van deze Tensor zal zijn:
print(float_vector.dtype)Geeft terug:
fakkel.float32Rekenkundige bewerkingen op tensoren
We kunnen twee tensoren toevoegen, net als alle wiskundige elementen, zoals:
tensor_1 = fakkel.tensor([2, 3, 4])tensor_2 = toorts.tensor([3, 4, 5])
tensor_1 + tensor_2
Het bovenstaande codefragment geeft ons:

Wij kunnen vermenigvuldigen een tensor met een scalair:
tensor_1 * 5Dit geeft ons:
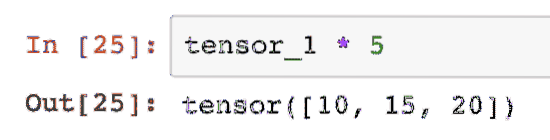
We kunnen een punt product ook tussen twee tensoren:
d_product = zaklamp.punt(tensor_1; tensor_2)d_product
Bovenstaand codefragment geeft ons de volgende uitvoer:
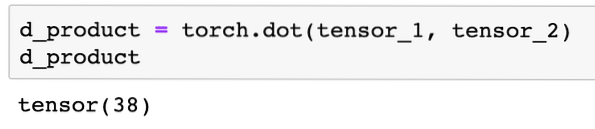
In de volgende sectie zullen we kijken naar hogere dimensies van Tensoren en matrices.
Matrix vermenigvuldiging
In deze sectie zullen we zien hoe we metrieken kunnen definiëren als tensoren en ze kunnen vermenigvuldigen, net zoals we vroeger deden in wiskunde op de middelbare school.
We zullen een matrix definiëren om mee te beginnen:
matrix = toorts.tensor([1, 3, 5, 6, 8, 0]).bekijken(2, 3)In het bovenstaande codefragment hebben we een matrix gedefinieerd met de tensorfunctie en vervolgens gespecificeerd met bekijk functie dat het moet worden gemaakt als een tweedimensionale tensor met 2 rijen en 3 kolommen. We kunnen meer argumenten geven aan de visie functie om meer afmetingen op te geven. Houd er rekening mee dat:
aantal rijen vermenigvuldigd met aantal kolommen = aantal itemsWanneer we de bovenstaande 2-dimensionale tensor visualiseren, zien we de volgende matrix:
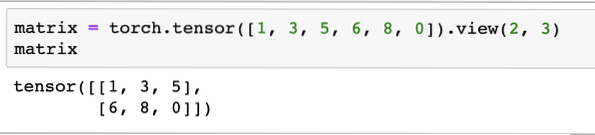
We zullen een andere identieke matrix met een andere vorm definiëren:
matrix_b = zaklamp.tensor([1, 3, 5, 6, 8, 0]).uitzicht(3, 2)We kunnen nu eindelijk de vermenigvuldiging uitvoeren:
fakkel.matmul(matrix, matrix_b)Bovenstaand codefragment geeft ons de volgende uitvoer:

Lineaire regressie met PyTorch
Lineaire regressie is een algoritme voor machinaal leren op basis van leertechnieken onder toezicht om regressieanalyses uit te voeren op onafhankelijke en een afhankelijke variabele. Al in de war? Laten we lineaire regressie in eenvoudige woorden definiëren.
Lineaire regressie is een techniek om de relatie tussen twee variabelen te achterhalen en te voorspellen hoeveel verandering in de onafhankelijke variabele veroorzaakt hoeveel verandering in de afhankelijke variabele. Een lineaire regressie-algoritme kan bijvoorbeeld worden toegepast om erachter te komen hoeveel prijsstijgingen voor een huis wanneer de oppervlakte met een bepaalde waarde wordt verhoogd. Of hoeveel pk in een auto aanwezig is op basis van het motorgewicht?. Het 2e voorbeeld klinkt misschien raar, maar je kunt altijd rare dingen proberen en wie weet kun je een relatie tussen deze parameters leggen met lineaire regressie!
De lineaire regressietechniek gebruikt meestal de vergelijking van een lijn om de relatie tussen de afhankelijke variabele (y) en de onafhankelijke variabele (x) weer te geven:
y = m * x + cIn de bovenstaande vergelijking:
- m = helling van curve
- c = bias (punt dat de y-as snijdt)
Nu we een vergelijking hebben die de relatie van onze use-case weergeeft, zullen we proberen enkele voorbeeldgegevens in te stellen samen met een plotvisualisatie. Hier zijn de voorbeeldgegevens voor huizenprijzen en hun grootte:
house_prices_array = [3, 4, 5, 6, 7, 8, 9]house_price_np = np.array(house_prices_array, dtype=np.vlotter32)
house_price_np = house_price_np.omvormen(-1,1)
house_price_tensor = Variabele(toorts.from_numpy(house_price_np))
huisgrootte = [ 7.5, 7, 6.5, 6.0, 5.5, 5.0, 4.5]
house_size_np = np.array(house_size, dtype=np.vlotter32)
house_size_np = house_size_np.omvormen(-1, 1)
house_size_tensor = Variabele(toorts.from_numpy(house_size_np))
# laten we onze gegevens visualiseren
matplotlib importeren.pyplot als plt
plt.scatter(house_prices_array, house_size_np)
plt.xlabel("Huisprijs $")
plt.ylabel("Huisgroottes")
plt.title("Huisprijs $ VS Huisgrootte")
plt
Merk op dat we gebruik hebben gemaakt van Matplotlib, een uitstekende visualisatiebibliotheek. Lees er meer over in de Matplotlib Tutorial. We zullen de volgende grafiekplot zien zodra we het bovenstaande codefragment uitvoeren:
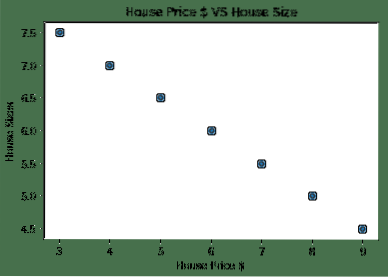
Wanneer we een lijn door de punten trekken, is deze misschien niet perfect, maar het is nog steeds voldoende voor het soort relatie dat de variabelen hebben. Nu we onze gegevens hebben verzameld en gevisualiseerd, willen we een voorspelling doen wat de grootte van het huis zal zijn als het voor $ 650.000 zou worden verkocht.
Het doel van het toepassen van lineaire regressie is om een lijn te vinden die past bij onze gegevens met een minimale fout. Hier zijn de stappen die we zullen uitvoeren om het lineaire regressiealgoritme toe te passen naar onze gegevens:
- Construeer een klasse voor lineaire regressie
- Definieer het model uit deze klasse Lineaire regressie
- Bereken de MSE (gemiddelde kwadratische fout)
- Voer optimalisatie uit om de fout te verminderen (SGD i.e. stochastische gradiëntafdaling)
- Voer terugpropagatie uit
- Maak tot slot de voorspelling
Laten we beginnen met het toepassen van bovenstaande stappen met de juiste import:
fakkel importerenvan fakkel.autograd import variabele
fakkel importeren.nn als nn
Vervolgens kunnen we onze Linear Regression-klasse definiëren die erft van PyTorch neurale netwerkmodule:
klasse LinearRegression(nn.module):def __init__(zelf,input_size,output_size):
# superfunctie erft van nn.Module zodat we toegang hebben tot alles van nn.module
super (lineaire regressie, zelf).__in het__()
# Lineaire functie
zelf.lineair = nn.Lineair(input_dim,output_dim)
def vooruit(zelf,x):
zelf terugkeren.lineair(x)
Nu we klaar zijn met de klasse, laten we ons model definiëren met een invoer- en uitvoergrootte van 1:
input_dim = 1output_dim = 1
model = LinearRegression (input_dim, output_dim)
We kunnen de MSE definiëren als:
mse = nn.MSEverlies()We zijn klaar om de optimalisatie te definiëren die kan worden uitgevoerd op de modelvoorspelling voor de beste prestaties:
# Optimalisatie (vind parameters die fouten minimaliseren)leersnelheid = 0.02
optimizer = toorts.optimaal.SGD(model).parameters(), lr=learning_rate)
We kunnen eindelijk een plot maken voor de verliesfunctie op ons model:
loss_list = []iteratie_nummer = 1001
voor iteratie in bereik (iteratienummer):
# optimalisatie uitvoeren zonder verloop
optimalisatieprogramma.zero_grad()
resultaten = model(huisprijs_tensor)
verlies = mse(resultaten, house_size_tensor)
# bereken afgeleide door achteruit te gaan
verlies.achteruit()
# Updaten van parameters
optimalisatieprogramma.stap()
# winkelverlies
loss_list.toevoegen (verlies).gegevens)
# afdrukverlies
if(iteratie % 50 == 0):
print('epoch , verlies '.formaat (iteratie, verlies).gegevens))
plt.plot (bereik (iteratienummer), verlieslijst)
plt.xlabel("Aantal iteraties")
plt.ylabel("Verlies")
plt
We hebben meerdere keren optimalisaties uitgevoerd op de verliesfunctie en proberen te visualiseren hoeveel verlies is toegenomen of afgenomen. Hier is de plot die de output is:
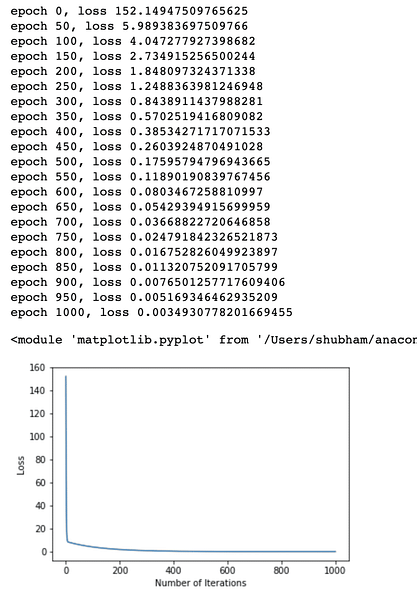
We zien dat naarmate het aantal iteraties hoger is, het verlies naar nul neigt. Dit betekent dat we klaar zijn om onze voorspelling te doen en te plotten:
# voorspel onze autoprijsvoorspeld = model(house_price_tensor).gegevens.numpy()
plt.scatter(house_prices_array, house_size, label = "originele gegevens", kleur = "rood")
plt.scatter (huisprijzen_array, voorspeld, label = "voorspelde gegevens", kleur = "blauw")
plt.legende()
plt.xlabel("Huisprijs $")
plt.ylabel ("Huisgrootte")
plt.title("Oorspronkelijke versus voorspelde waarden")
plt.tonen()
Hier is de plot die ons zal helpen om de voorspelling te maken:
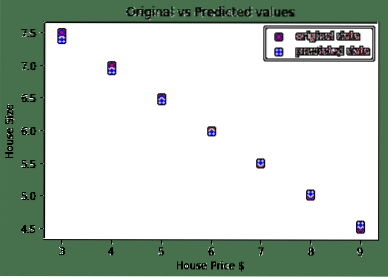
Conclusie
In deze les hebben we gekeken naar een uitstekend rekenpakket waarmee we sneller en efficiënter voorspellingen kunnen doen en nog veel meer. PyTorch is populair vanwege de manier waarop we neurale netwerken op een fundamentele manier kunnen beheren met Tensors.


