R compileren en uitvoeren vanaf de opdrachtregel
De twee manieren om R-programma's uit te voeren zijn: een R-script, dat veel wordt gebruikt en de meeste voorkeur heeft, en de tweede is R CMD BATCH, het is geen veelgebruikte opdracht. We kunnen ze rechtstreeks vanaf de opdrachtregel of een andere taakplanner bellen.
Je kunt deze opdrachten mogelijk aanroepen vanuit een shell die in de IDE is ingebouwd en tegenwoordig wordt de RStudio IDE geleverd met tools die het R-script en de R CMD BATCH-functies verbeteren of beheren.
source() functie binnen R is een goed alternatief voor het gebruik van de opdrachtregel. Deze functie kan ook een script aanroepen, maar om deze functie te gebruiken, moet je binnen de R-omgeving zijn.
R Taal Ingebouwde datasets
Om de datasets weer te geven die zijn ingebouwd in R, gebruikt u de opdracht data() en zoekt u vervolgens wat u zoekt en gebruikt u de naam van de dataset in de functie data(). Vind ik leuk data (functienaam).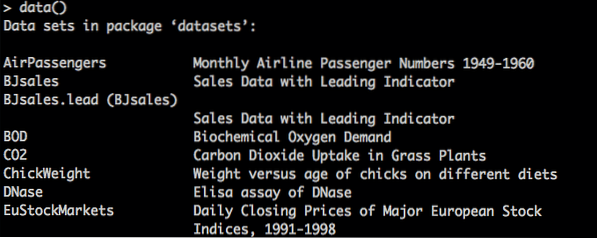
Toon datasets in R
Het vraagteken (?) kan worden gebruikt om hulp te vragen voor datasets.
Gebruik samenvatting () om alles te controleren.
Plot () is ook een functie die wordt gebruikt om grafieken te plotten.
Laten we een testscript maken en het uitvoeren. Aanmaken p1.R bestand en sla het op in de thuismap met de volgende inhoud:
Codevoorbeeld:
# Eenvoudige hallo wereld-code in R print ("Hallo wereld!") print("LinuxHint") print(5+6) 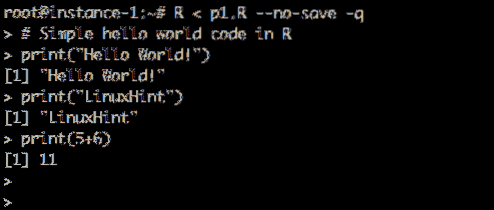
Hardlopen Hallo Wereld
R-gegevensframes
Voor het opslaan van gegevens in tabellen gebruiken we een structuur in R genaamd a Gegevensframe. Het wordt gebruikt om vectoren van gelijke lengte weer te geven. De volgende variabele nm is bijvoorbeeld een gegevensframe met drie vectoren x, y, z:
x = c(2, 3, 5) y = c("aa", "bb", "cc") z = c(TRUE, FALSE, TRUE) # nm is een dataframe nm = data.frame(n, s, b) Er is een concept genaamd IngebouwdDataframes ook in R. mtcars is zo'n ingebouwd dataframe in R, dat we als voorbeeld zullen gebruiken voor een beter begrip. Zie onderstaande code:
> mtcars mpg cyl disp hp drat wt… Mazda RX4 21.0 6 160 110 3.90 2.62… bus RX4 Wag 21.0 6 160 110 3.90 2.88… Datsun 710 22.8 4 108 93 3.85 2.32…
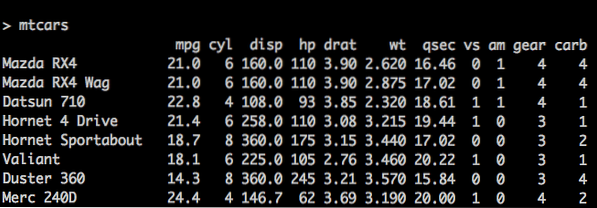
mtcars bulitin dataframe
De kop is de bovenste regel van de tabel die de kolomnamen bevat. Gegevensrijen worden gedoneerd door elke horizontale lijn; elke regel begint met de naam van de rij en wordt dan gevolgd door de feitelijke gegevens. Het gegevenslid van een rij wordt een cel genoemd.
We zouden de rij- en kolomcoördinaten invoeren in een enkele vierkante haak '[]'-operator om gegevens in een cel op te halen. Om de coördinaten te scheiden, gebruiken we een komma. De bestelling is essentieel. De coördinaat begint met rij, dan komma en eindigt dan met de kolom. Celwaarde van 2nd rij en 1st kolom wordt gegeven als:
> mtcars[2, 2] [1] 6
We kunnen ook rij- en kolomnaam gebruiken in plaats van coördinaten:
> mtcars ["Bus RX4", "mpg"] [1] 6
nrow-functie wordt gebruikt om het aantal rijen in het dataframe te vinden.
> nrow(mtcars) # aantal gegevensrijen [1] 32
ncol-functie wordt gebruikt om het aantal kolommen in een dataframe te vinden.
> ncol(mtcars) # aantal kolommen [1] 11
R Programmeerlussen
Onder sommige omstandigheden gebruiken we lussen wanneer we een deel van de code willen automatiseren, of als we een reeks instructies willen herhalen.
For-lus in R
Als we deze jaargegevens meer dan één keer willen afdrukken.
print(paste("Het jaar is", 2000)) "Het jaar is 2000" print(paste("Het jaar is", 2001)) "Het jaar is 2001" print(paste("Het jaar is", 2002) ) "Het jaar is 2002" print(paste("Het jaar is", 2003)) "Het jaar is 2003" print(paste("Het jaar is", 2004)) "Het jaar is 2004" print(paste(" Het jaar is", 2005)) "Het jaar is 2005" In plaats van onze verklaring keer op keer te herhalen als we voor lus zal het veel gemakkelijker voor ons zijn. Soortgelijk:
for (jaar in c(2000,2001,2002,2003,2004,2005)) print(paste("Het jaar is", jaar)) "Het jaar is 2000" "Het jaar is 2001" "Het jaar is 2002" "Het jaar is 2003" "Het jaar is 2004" "Het jaar is 2005" Terwijl lus in R
while (uitdrukking) statement
Als het resultaat van expressie TRUE is, wordt de hoofdtekst van de lus ingevoerd. De instructies in de lus worden uitgevoerd en de stroom keert terug om de uitdrukking opnieuw te beoordelen. De lus herhaalt zichzelf totdat de uitdrukking FALSE evalueert, in welk geval de lus wordt afgesloten.
Voorbeeld van while-lus:
# i wordt aanvankelijk geïnitialiseerd op 0 i = 0 terwijl (i<5) print (i) i=i+1 Output: 0 1 2 3 4
In de bovenstaande while-lus is de uitdrukking ik<5welke meet naar TRUE aangezien 0 kleiner is dan 5. Daarom wordt het lichaam van de lus uitgevoerd, en ik wordt uitgevoerd en verhoogd. Het is belangrijk om te verhogen ik binnen de lus, dus het zal op een of andere manier aan de voorwaarde voldoen. In de volgende lus, de waarde van ik is 1, en de lus gaat verder. Het zal zich herhalen totdat ik is gelijk aan 5 wanneer de voorwaarde 5<5 reached loop will give FALSE and the while loop will exit.
R-functies
om een te maken functie we gebruiken de richtlijnfunctie (). In het bijzonder zijn het R-objecten van klasse functie.
f <- function() ##some piece of instructions
Met name functies kunnen worden doorgegeven aan andere functies omdat argumenten en functies kunnen worden genest, zodat u een functie binnen een andere functie kunt bepalen.
Functies kunnen optioneel enkele benoemde argumenten hebben die standaardwaarden hebben. Als u geen standaardwaarde wilt, kunt u de waarde instellen op NULL.
Enkele feiten over R-functieargumenten:
- De argumenten die zijn toegelaten in de functiedefinitie zijn de formele argumenten
- De functie formals kan een lijst van alle formele argumenten van een functie teruggeven
- Niet elke functieaanroep in R gebruikt alle formele argumenten
- Functieargumenten kunnen standaardwaarden hebben, of ze kunnen ontbreken
#Een functie definiëren: f <- function (x, y = 1, z = 2, s= NULL)
Een logistisch regressiemodel maken met ingebouwde dataset
De glm() functie wordt gebruikt in R om de logistische regressie te passen. glm() functie is vergelijkbaar met de lm() maar glm() heeft enkele extra parameters. Het formaat ziet er als volgt uit:
glm(X~Z1+Z2+Z3, family=binomiaal (link=”logit”), data=mijngegevens)
X is afhankelijk van de waarden van Z1, Z2 en Z3. Wat betekent dat Z1, Z2 en Z3 onafhankelijke variabelen zijn en X de afhankelijke variabele is. Functie omvat een extra parameterfamilie en heeft een binomiale waarde (link = "logit"), wat betekent dat de linkfunctie logit is en de kansverdeling van het regressiemodel binomiaal is.
Stel we hebben een voorbeeld van een student waar hij toelating krijgt op basis van twee examenresultaten. De dataset bevat de volgende items:
- resultaat _1- Resultaat-1 score
- resultaat _2- Resultaat -2 score
- toegelaten-1 indien toegelaten of 0 indien niet toegelaten
In dit voorbeeld hebben we twee waarden 1 als een student toelating kreeg en 0 als hij geen toelating kreeg. We moeten een model genereren om te voorspellen of de student toegelaten is of niet,. Voor een bepaald probleem wordt toegelaten beschouwd als een afhankelijke variabele, examen_1 en examen_2 worden beschouwd als onafhankelijke variabelen. Voor dat model wordt onze R-code gegeven
>Model_1<-glm(admitted ~ result_1 +result_2, family = binomial("logit"), data=data) Stel dat we twee resultaten hebben van de student. Resultaat-1 65% en resultaat-2 90%, nu zullen we voorspellen of de student wel of niet wordt toegelaten voor het schatten van de kans dat de student wordt toegelaten, onze R-code is als volgt:
>in_frame<-data.frame(result_1=65,result_2=90) >predict(Model_1,in_frame, type="response") Uitvoer: 0.9894302
De bovenstaande uitvoer toont ons de kans tussen 0 en 1. Als het dan kleiner is dan 0.5 het betekent dat de student geen toelating heeft gekregen. In deze toestand is het ONWAAR. Als het groter is dan 0.5, wordt de voorwaarde als WAAR beschouwd, wat betekent dat de student is toegelaten. We moeten de functie round () gebruiken om de kans te voorspellen tussen 0 en 1.
R-code daarvoor is zoals hieronder weergegeven:
>round(predict(Model_1, in_frame, type="respons"))[/code] Uitvoer: 1
Een student krijgt toelating omdat de output 1 . is. Bovendien kunnen we op dezelfde manier ook andere waarnemingen voorspellen predict.
Logistiek regressiemodel gebruiken (scoren) met nieuwe gegevens
Indien nodig kunnen we het model in een bestand opslaan. R-code voor ons treinmodel ziet er als volgt uit:
het model <- glm(my_formula, family=binomial(link='logit'),data=model_set)
Dit model kan worden opgeslagen met:
opslaan(bestand="bestandsnaam",het_bestand)
Je kunt het bestand gebruiken nadat je het hebt opgeslagen, door die R-code te gebruiken:
laden (bestand = "bestandsnaam")
Voor het toepassen van het model voor nieuwe gegevens kunt u deze regel van een code gebruiken:
model_set$pred <- predict(the_model, newdata=model_set, type="response")
OPMERKING: De model_set kan aan geen enkele variabele worden toegewezen. Om een model te laden gebruiken we de functie load(). Nieuwe waarnemingen veranderen niets aan het model. Het model blijft hetzelfde. We gebruiken het oude model om voorspellingen te doen over de nieuwe gegevens om niets in het model te veranderen.
Conclusie
Ik hoop dat je hebt gezien hoe R-programmering op een eenvoudige manier werkt en hoe je snel in actie kunt komen door machine learning en statistiekcodering met R te doen.

