ZFS: concepten en zelfstudie
Op uw zoektocht naar gegevensintegriteit is het gebruik van OpenZFS onvermijdelijk. Het zou zelfs heel jammer zijn als je iets anders dan ZFS gebruikt voor het opslaan van je waardevolle gegevens. Veel mensen aarzelen echter om het uit te proberen. De reden hiervoor is dat een bestandssysteem op bedrijfsniveau met een breed scala aan ingebouwde functies, ZFS moeilijk te gebruiken en te beheren moet zijn. Niets is minder waar. ZFS gebruiken is zo eenvoudig als maar kan. Met een handvol terminologieën en nog minder opdrachten bent u klaar om ZFS overal te gebruiken - van de onderneming tot uw NAS thuis/kantoor.
In de woorden van de makers van ZFS: "We willen het toevoegen van opslag aan uw systeem net zo eenvoudig maken als het toevoegen van nieuwe RAM-sticks.”
We zullen later zien hoe dat wordt gedaan. Ik zal FreeBSD 11 gebruiken.1 om de onderstaande tests uit te voeren, zijn de opdrachten en de onderliggende architectuur vergelijkbaar voor alle Linux-distributies die OpenZFS ondersteunen.
De volledige ZFS-stack kan in de volgende lagen worden ingedeeld:
- Opslagproviders - draaiende schijven of SSD's
- Vdevs - Groepering van opslagproviders in verschillende RAID-configuraties
- Zpools - Aggregatie van vdevs in een enkele opslagpool
- Z-Filesystems - Datasets met coole functies zoals compressie en reservering.
Zpool maken
Laten we om te beginnen beginnen met een installatie van waar we zes schijven van 20 GB hebben ada[1-6]
$ls -al /dev/ada?
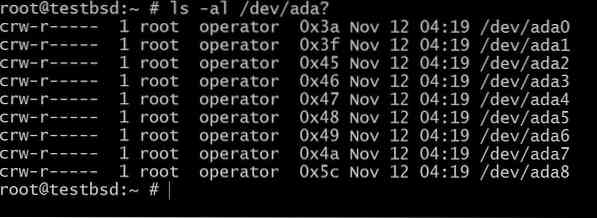
De ada0 is waar het besturingssysteem is geïnstalleerd. De rest wordt gebruikt voor deze demonstratie.
De namen van uw schijven kunnen verschillen, afhankelijk van het type interface dat wordt gebruikt. Typische voorbeelden zijn: da0, ada0, acd0 en CD. naar binnen kijken/devgeeft u een idee van wat er beschikbaar is.
EEN zpool is gemaakt door zpool maken opdracht:
$zpool create OurFirstZpool ada1 ada2 ada3 # En voer dan de volgende opdracht uit: $zpool status
We zullen een nette uitvoer zien die ons gedetailleerde informatie over het zwembad geeft:
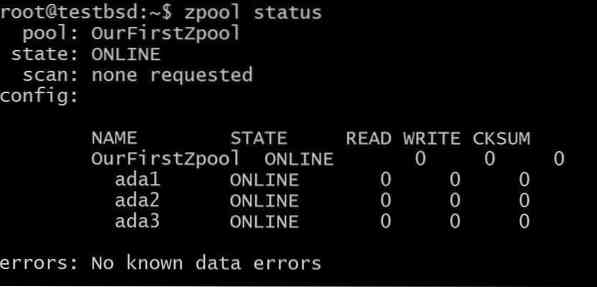
Dit is de eenvoudigste zpool zonder redundantie of fouttolerantie... Elke schijf is zijn eigen vdev.
U krijgt echter nog steeds alle ZFS-goedheid zoals controlesommen voor elk gegevensblok dat wordt opgeslagen, zodat u op zijn minst kunt detecteren of de gegevens die u hebt opgeslagen beschadigd raken.
Bestandssystemen, een.k.a datasets, kan nu op de volgende manier bovenop deze pool worden aangemaakt:
$zfs maakt OurFirstZpool/dataset1
Gebruik nu uw vertrouwde df -h commando of voer uit:
$zfs-lijst
Om de eigenschappen van uw nieuw aangemaakte bestandssysteem te zien:

Merk op hoe de volledige ruimte die wordt aangeboden door de drie schijven (vdevs) beschikbaar is voor het bestandssysteem. Dit geldt voor alle bestandssystemen die u in de pool aanmaakt, tenzij we anders specificeren.
Als u een nieuwe schijf (vdev) wilt toevoegen, ada4, u kunt dit doen door te draaien:
$zpool voeg OurFirstZpool toe ada4
Als je nu de staat van je bestandssysteem ziet

De beschikbare grootte is nu gegroeid zonder extra gedoe met het vergroten van de partitie of het maken van een back-up en het herstellen van de gegevens op het bestandssysteem.
Virtuele apparaten - Vdevs
Vdev's zijn de bouwstenen van een zpool, de meeste redundantie en prestaties hangen af van de manier waarop uw schijven zijn gegroepeerd in deze, zogenaamde vdevs . Laten we eens kijken naar enkele van de belangrijkste soorten vdevs:
1. RAID 0 of strepen
Elke schijf fungeert als zijn eigen vdev. Geen gegevensredundantie en de gegevens zijn verspreid over alle schijven. Ook bekend als striping. Het falen van een enkele schijf zou betekenen dat de hele zpool onbruikbaar wordt. Bruikbare opslag is gelijk aan de som van alle beschikbare opslagapparaten.
De eerste zpool die we in de vorige sectie hebben gemaakt, is een RAID 0 of gestreepte opslagarray.
2. RAID 1 of Mirror
Gegevens worden gespiegeld tussen neeschijven. De werkelijke capaciteit van de vdev wordt beperkt door de onbewerkte capaciteit van de kleinste schijf daarin nee-schijfarray. Gegevens worden gespiegeld tussen nee schijven, dit betekent dat u bestand bent tegen het falen van n-1 schijven.
Gebruik het trefwoord mirror om een gespiegelde array te maken:
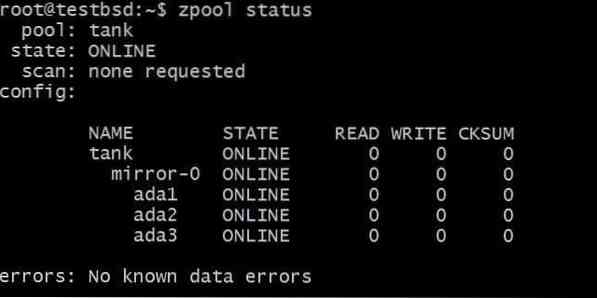
$zpool maak tankspiegel ada1 ada2 ada3
De gegevens die zijn geschreven naar tank zpool wordt gespiegeld tussen deze drie schijven en de daadwerkelijk beschikbare opslagruimte is gelijk aan de grootte van de kleinste schijf, die in dit geval ongeveer 20 GB is.
In de toekomst wilt u misschien meer schijven aan deze pool toevoegen, en er zijn twee mogelijke dingen die u kunt doen:. Bijvoorbeeld zpool tank heeft drie schijven die gegevens spiegelen als een enkele vdev mirror-0:
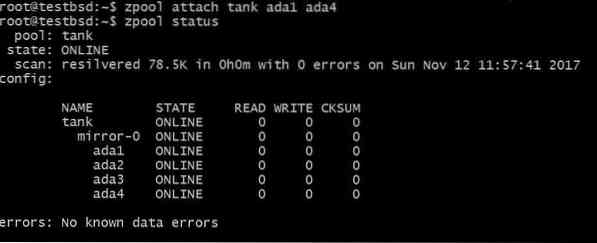
Misschien wilt u een extra schijf toevoegen, bijvoorbeeld: ada4, om dezelfde gegevens te spiegelen. Dit kan door het commando uit te voeren:
$zpool bevestig tank ada1 ada4
Dit zou een extra schijf toevoegen aan de vdev die de schijf al heeft ada1 erin, maar niet om de beschikbare opslagruimte te vergroten.
Op dezelfde manier kunt u schijven loskoppelen van een mirror door het volgende uit te voeren:
$zpool tank losmaken ada4
Aan de andere kant wil je misschien een extra vdev toevoegen om de capaciteit van zpool te vergroten. Dat kan met het zpool add-commando:
$zpool tankspiegel toevoegen ada4 ada5 ada6
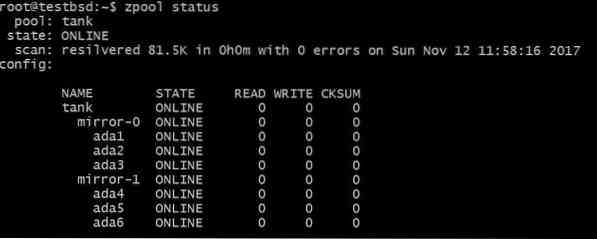
Met de bovenstaande configuratie kunnen gegevens worden gestript over vdevs mirror-0 en mirror-1. U kunt in dit geval 2 schijven per vdev verliezen en uw gegevens zijn nog steeds intact. Totale bruikbare ruimte neemt toe tot 40 GB.
3. RAID-Z1, RAID-Z2 en RAID-Z3
Als een vdev van het type RAID-Z1 is, moet hij ten minste 3 schijven gebruiken en de vdev kan de ondergang van slechts één van die schijven tolereren. RAID-Z-configuraties staan het niet toe om schijven rechtstreeks op een vdev . te bevestigen. Maar u kunt meer vdevs toevoegen met zpool toevoegen, zodat de capaciteit van het zwembad kan blijven toenemen.
RAID-Z2 zou minimaal 4 schijven per vdev vereisen en kan tot 2 schijfstoringen tolereren en als de derde schijf uitvalt voordat de 2 schijven zijn vervangen, gaan uw waardevolle gegevens verloren. Hetzelfde geldt voor RAID-Z3, waarvoor minimaal 5 schijven per vdev nodig zijn, met maximaal 3 schijven met fouttolerantie voordat herstel hopeloos wordt.
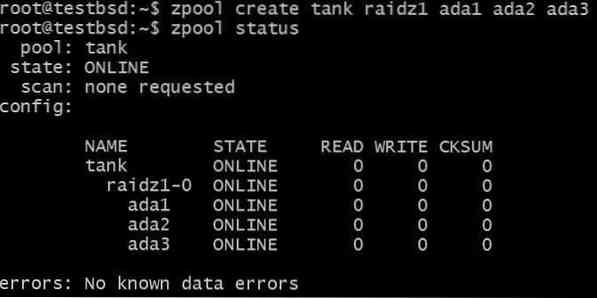
Laten we een RAID-Z1-pool maken en deze laten groeien:
$zpool maak tank raidz1 ada1 ada2 ada3
De pool gebruikt drie schijven van 20 GB, waardoor 40 GB beschikbaar is voor de gebruiker.
Voor het toevoegen van nog een vdev zijn 3 extra schijven nodig:
$zpool tank raidz1 ada4 ada5 ada6 toevoegen
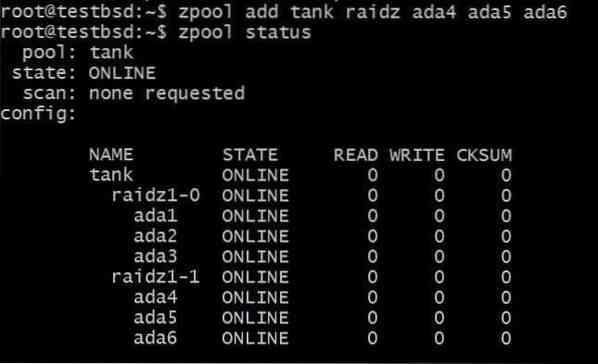
De totale bruikbare gegevens zijn nu 80 GB en u kunt tot 2 schijven verliezen (één van elke vdev) en nog steeds hoop op herstel hebben.
Conclusie
Nu weet u genoeg over ZFS om al uw gegevens er met vertrouwen in te importeren. Vanaf hier kun je verschillende andere functies opzoeken die ZFS biedt, zoals het gebruik van snelle NVMe's voor lees- en schrijfcaches, het gebruik van ingebouwde compressie voor je datasets en in plaats van je te laten overweldigen door alle beschikbare opties, zoek je gewoon naar wat je nodig hebt voor je specifieke use-case.
Ondertussen zijn er nog een paar handige tips met betrekking tot de keuze van hardware die u moet volgen:
- Gebruik nooit hardware RAID-controller met ZFS.
- Error Correcting RAM (ECC) wordt aanbevolen, maar is niet verplicht
- Gegevensdeduplicatiefunctie verbruikt veel geheugen, gebruik in plaats daarvan compressie.
- Gegevensredundantie is geen alternatief voor back-up. Heb meerdere back-ups, sla die back-ups op met ZFS!


