Big data zijn gegevens in de orde van terabytes of petabytes en meer, bestaande uit mining, analyse en voorspellende modellering van grote datasets. De snelle groei van informatie en technologische ontwikkelingen heeft individuen en ondernemingen over de hele wereld een unieke kans geboden om winst te maken en nieuwe mogelijkheden te ontwikkelen die traditionele bedrijfsmodellen herdefiniëren met behulp van grootschalige analyses.
Dit artikel biedt een overzicht van vijf van de meest populaire open source dataplatforms data. Hier is onze lijst:
Apache Hadoop
Apache Hadoop is een open source softwareplatform dat zeer grote datasets verwerkt in een gedistribueerde omgeving met betrekking tot opslag en rekenkracht, en is voornamelijk gebouwd op goedkope basishardware.
Apache Hadoop is ontworpen om eenvoudig op te schalen van enkele naar duizenden servers. Het helpt u om lokaal opgeslagen gegevens te verwerken in een algemene parallelle verwerkingsconfiguratie. Een van de voordelen van Hadoop is dat het fouten op softwareniveau afhandelt. De volgende afbeelding illustreert de algehele architectuur van het Hadoop-ecosysteem en waar de verschillende kaders zich daarin bevinden:
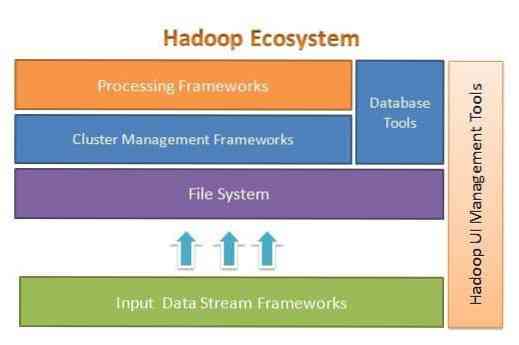
Apache Hadoop biedt een raamwerk voor de bestandssysteemlaag, de clusterbeheerlaag en de verwerkingslaag. Het laat een optie open voor andere projecten en frameworks om naast Hadoop Ecosystem te komen werken en hun eigen framework te ontwikkelen voor elk van de beschikbare lagen in het systeem.
Apache Hadoop bestaat uit vier hoofdmodules. Deze modules zijn Hadoop Distributed File System (de bestandssysteemlaag), Hadoop MapReduce (die werkt met zowel clusterbeheer als de verwerkingslaag), Yet Another Resource Negotiator (YARN, de clusterbeheerlaag) en Hadoop Common.
Elastisch zoeken
Elasticsearch is een op volledige tekst gebaseerde zoek- en analyse-engine. Het is een zeer schaalbaar en gedistribueerd systeem, speciaal ontworpen om efficiënt en snel te werken met big data-systemen, waarbij loganalyse een van de belangrijkste use-cases is. Het is in staat om geavanceerde en complexe zoekopdrachten uit te voeren, en bijna realtime te verwerken voor geavanceerde analyses en operationele intelligentie.
Elasticsearch is geschreven in Java en is gebaseerd op Apache Lucene. Uitgebracht in 2010 en snel populair geworden vanwege de flexibele datastructuur, schaalbare architectuur en zeer snelle responstijd. Elasticsearch is gebaseerd op een JSON-document met een schemavrije structuur, waardoor adoptie eenvoudig en probleemloos is. Het is een van de best gerangschikte zoekmachines van enterprise-klasse. U kunt de client in elke programmeertaal schrijven; Elasticsearch werkt officieel met Java, .NET, PHP, Python, Perl, enzovoort.
Elasticsearch werkt voornamelijk samen met behulp van een REST API. Het krijgt gegevens in de vorm van JSON-documenten met alle vereiste parameters en geeft zijn antwoord op een vergelijkbare manier.
MongoDB
MongoDB is een NoSQL-database op basis van het documentopslaggegevensmodel. In MongoDB is alles een verzameling of document. Om MongoDB-terminologie te begrijpen, is verzameling een alternatief woord voor tabel, terwijl document een alternatief woord is voor rijen.
MongoDB is een open source, documentgeoriënteerde en platformonafhankelijke database. Het is voornamelijk geschreven in C++. Het is ook de toonaangevende NoSQL-database die hoge prestaties, hoge beschikbaarheid en eenvoudige schaalbaarheid biedt. MongoDB gebruikt JSON-achtige documenten met schema en biedt uitgebreide ondersteuning voor query's. Enkele van de belangrijkste functies zijn indexering, replicatie, taakverdeling, aggregatie en bestandsopslag.
Cassandra
Cassandra is een open source Apache-project ontworpen voor NoSQL-databasebeheer database. Cassandra-rijen zijn georganiseerd in tabellen en geïndexeerd door een sleutel. Het maakt gebruik van een alleen-toevoegende, op logs gebaseerde opslagengine. Gegevens in Cassandra worden gedistribueerd over meerdere masterless nodes, zonder single point of failure. Het is een Apache-project op het hoogste niveau en de ontwikkeling ervan staat momenteel onder toezicht van de Apache Software Foundation (ASF).
Cassandra is ontworpen om problemen op te lossen die samenhangen met het werken op grote (web)schaal. Gezien Cassandra's masterless architectuur, is het in staat om operaties uit te voeren ondanks een klein (zij het significant) aantal hardwarestoringen. Cassandra draait op meerdere knooppunten in meerdere datacenters. Het repliceert gegevens in deze datacenters om storingen of downtime te voorkomen. Dit maakt het een zeer fouttolerant systeem.
Cassandra gebruikt zijn eigen programmeertaal om toegang te krijgen tot gegevens op alle knooppunten. Het heet Cassandra Query Language of CQL. Het is vergelijkbaar met SQL, dat voornamelijk wordt gebruikt door relationele databases. CQL kan worden gebruikt door zijn eigen applicatie genaamd cqlsh . uit te voeren. Cassandra biedt ook veel integratie-interfaces voor meerdere programmeertalen om een applicatie te bouwen met Cassandra. De integratie-API ondersteunt Java, C++, Python en andere.
Apache HBase
HBase is een ander Apache-project dat is ontworpen om de NoSQL-gegevensopslag te beheren. Het is ontworpen om gebruik te maken van de functies van Hadoop Ecosystem, waaronder betrouwbaarheid, fouttolerantie, enzovoort. Het gebruikt HDFS als bestandssysteem voor opslagdoeleinden. Er zijn meerdere datamodellen waarmee NoSQL werkt en Apache HBase behoort tot het kolomgeoriënteerde datamodel. HBase was oorspronkelijk gebaseerd op Google Big Table, dat ook gerelateerd is aan het kolomgeoriënteerde model voor ongestructureerde gegevens.
HBase slaat alles op in de vorm van een sleutel-waardepaar. Het belangrijkste om op te merken is dat in HBase een sleutel en een waarde in de vorm van bytes zijn. Dus om informatie in HBase op te slaan, moet u informatie omzetten in bytes. (Met andere woorden, de API accepteert niets anders dan byte-array.) Wees voorzichtig met HBase, want wanneer u gegevens opslaat, moet u het oorspronkelijke type onthouden. Gegevens die oorspronkelijk een tekenreeks waren, worden geretourneerd als een bytearray als ze onjuist worden opgeroepen. Als gevolg hiervan zal het een bug in uw applicatie creëren en uw applicatie laten crashen.
Ik hoop dat je genoten hebt van dit artikel. Als u op zoek bent naar het ontwerpen en ontwerpen van data-intensieve applicaties, dan kunt u Anuj Kumar's . verkennen Architecten van data-intensieve applicaties. Dit boek is uw toegangspoort om slimme data-intensieve systemen te bouwen door de belangrijkste data-intensieve architecturale principes, patronen en technieken rechtstreeks in uw applicatie-architectuur op te nemen.


