Apache Solr
Apache Solr is een van de meest populaire NoSQL-databases die kan worden gebruikt om gegevens op te slaan en in bijna realtime op te vragen. Het is gebaseerd op Apache Lucene en is geschreven in Java. Net als Elasticsearch ondersteunt het databasequery's via REST API's. Dit betekent dat we eenvoudige HTTP-aanroepen kunnen gebruiken en HTTP-methoden kunnen gebruiken zoals GET, POST, PUT, DELETE enz. om toegang te krijgen tot gegevens. Het biedt ook een optie om in de vorm van XML of JSON te komen via de REST API's.
In deze les zullen we bestuderen hoe Apache Solr op Ubuntu te installeren en ermee aan de slag te gaan via een basisset databasequery's.
Java installeren
Om Solr op Ubuntu te installeren, moeten we eerst Java installeren. Java is mogelijk niet standaard geïnstalleerd. We kunnen het verifiëren door dit commando te gebruiken:
java -versieWanneer we deze opdracht uitvoeren, krijgen we de volgende uitvoer: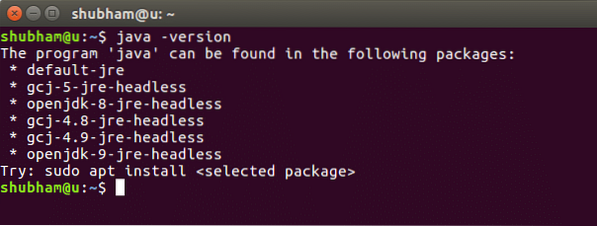
We gaan nu Java op ons systeem installeren. Gebruik hiervoor deze opdracht:
sudo add-apt-repository ppa:webupd8team/javasudo apt-get update
sudo apt-get install oracle-java8-installer
Zodra deze opdrachten zijn uitgevoerd, kunnen we opnieuw verifiëren dat Java nu is geïnstalleerd met dezelfde opdracht.
Apache Solr installeren
We beginnen nu met het installeren van Apache Solr, wat eigenlijk slechts een kwestie is van een paar commando's.
Om Solr te installeren, moeten we weten dat Solr niet op zichzelf werkt en draait, maar dat het een Java Servlet-container nodig heeft om bijvoorbeeld Jetty- of Tomcat Servlet-containers uit te voeren. In deze les gebruiken we de Tomcat-server, maar het gebruik van Jetty is redelijk vergelijkbaar.
Het goede aan Ubuntu is dat het drie pakketten biedt waarmee Solr eenvoudig kan worden geïnstalleerd en gestart. Zij zijn:
- solr-gemeenschappelijk
- solr-kater
- solr-steiger
Het is duidelijk dat solr-common nodig is voor beide containers, terwijl solr-jetty nodig is voor Jetty en solr-tomcat alleen nodig is voor Tomcat-server. Omdat we Java al hebben geïnstalleerd, kunnen we het Solr-pakket downloaden met deze opdracht:
sudo wget http://www-eu.apache.org/dist/lucene/solr/7.2.1/solr-7.2.1.zipOmdat dit pakket veel pakketten met zich meebrengt, inclusief Tomcat-server, kan dit een paar minuten duren om alles te downloaden en te installeren. Download hier de nieuwste versie van Solr-bestanden.
Nadat de installatie is voltooid, kunnen we het bestand uitpakken met de volgende opdracht:
unzip -q solr-7.2.1.zipVerander nu uw map in het zipbestand en u zult de volgende bestanden erin zien:
Apache Solr Node starten
Nu we Apache Solr-pakketten op onze machine hebben gedownload, kunnen we als ontwikkelaar meer doen vanuit een knooppuntinterface, dus we zullen een knooppuntinstantie voor Solr starten waar we daadwerkelijk verzamelingen kunnen maken, gegevens kunnen opslaan en doorzoekbare zoekopdrachten kunnen maken.
Voer de volgende opdracht uit om de clusterconfiguratie te starten:
./bin/solr start -e cloudWe zullen de volgende uitvoer zien met deze opdracht: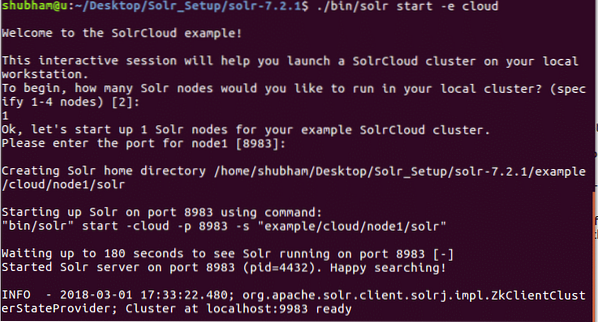
Er zullen veel vragen worden gesteld, maar we zullen een Solr-cluster met één knooppunt opzetten met alle standaardconfiguraties. Zoals te zien is in de laatste stap, is de Solr-knooppuntinterface beschikbaar op:
waarbij 8983 de standaardpoort is voor het knooppunt. Zodra we de bovenstaande URL bezoeken, zien we de Node-interface: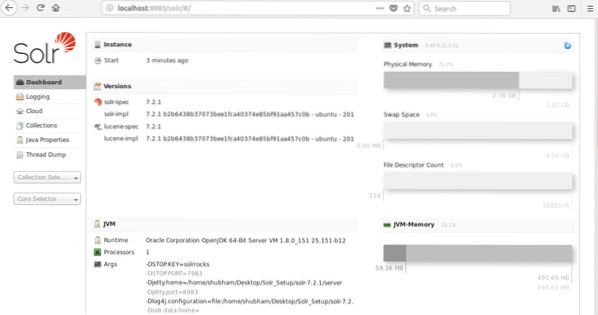
Verzamelingen gebruiken in Solr
Nu onze knooppuntinterface actief is, kunnen we een verzameling maken met de opdracht:
./bin/solr create_collection -c linux_hint_collectionen we zullen de volgende uitvoer zien:
Vermijd de waarschuwingen voor nu. We kunnen de verzameling nu zelfs in de Node-interface zien:
Nu kunnen we beginnen met het definiëren van een schema in Apache Solr door de schemasectie te selecteren: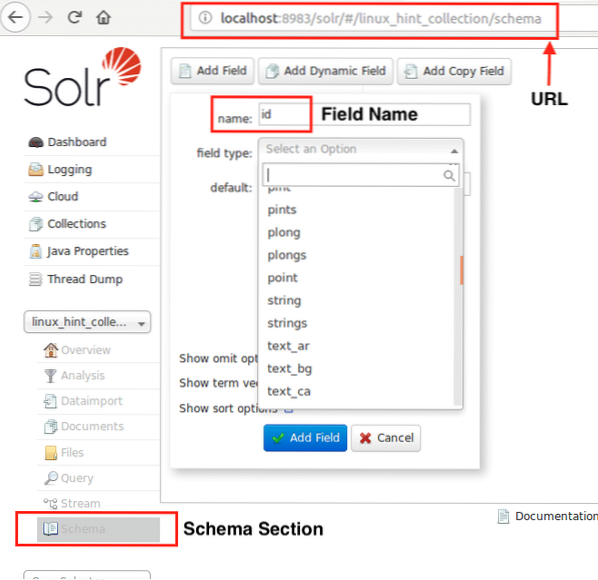
We kunnen nu beginnen met het invoegen van gegevens in onze collecties. Laten we hier een JSON-document in onze collectie invoegen:
curl -X POST -H 'Inhoudstype: applicatie/json''http://localhost:8983/solr/linux_hint_collection/update/json/docs' --data-binary '
"id": "iduye",
"naam": "Shubham"
'
We zullen een succesreactie zien tegen deze opdracht:
Laten we als laatste opdracht eens kijken hoe we alle gegevens uit de Solr-verzameling kunnen KRIJGEN:
We zullen de volgende uitvoer zien:


