- Wat is het Panda's-pakket?
- Installatie en aan de slag
- Gegevens laden van CSV's in Pandas DataFrame
- Wat is DataFrame en hoe werkt het?
- Gegevensframes snijden
- Wiskundige bewerkingen via DataFrame
Dit lijkt veel om te dekken. Laten we nu beginnen.
Wat is het Python Pandas-pakket??
Volgens de Pandas-homepage: pandas is een open source bibliotheek met BSD-licentie die krachtige, gebruiksvriendelijke datastructuren en data-analysetools voor de programmeertaal Python biedt.
Een van de coolste dingen van Panda's is dat het het lezen van gegevens uit veelgebruikte gegevensformaten zoals CSV, SQL enz. mogelijk maakt. zeer eenvoudig, waardoor het even bruikbaar is in productietoepassingen of slechts enkele demo-toepassingen.
Python-panda's installeren
Even een opmerking voordat we het installatieproces starten, we gebruiken een virtuele omgeving voor deze les die we hebben gemaakt met het volgende commando:
python -m virtualenv panda'sbron panda's/bin/activeren
Zodra de virtuele omgeving actief is, kunnen we de panda-bibliotheek in de virtuele omgeving installeren, zodat voorbeelden die we vervolgens maken, kunnen worden uitgevoerd:
pip installeer panda'sOf we kunnen Conda gebruiken om dit pakket te installeren met de volgende opdracht:
conda installeer panda'sWe zien zoiets als dit wanneer we het bovenstaande commando uitvoeren:
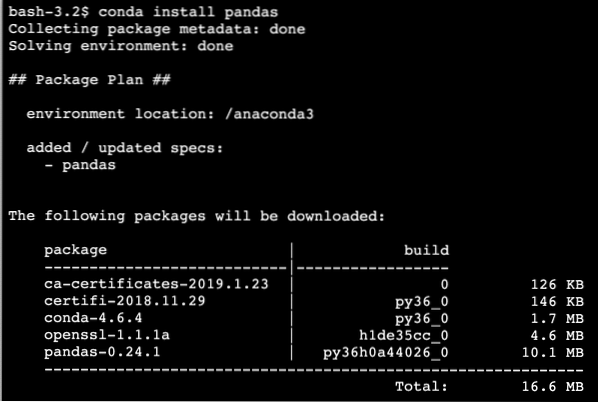
Zodra de installatie is voltooid met Conda, kunnen we het pakket in onze Python-scripts gebruiken als:
panda's importeren als pdLaten we nu Panda's in onze scripts gaan gebruiken.
CSV-bestand lezen met Pandas DataFrames
Een CSV-bestand lezen is eenvoudig met Pandas. Ter demonstratie hebben we een klein CSV-bestand gemaakt met de volgende inhoud:
Naam, RollNo, Datum van opname, Contactpersoon voor noodgevallenShubham,1,20-05-2012,9988776655
Gagan, 2,20-05-2009,8364517829
Oshima, 3,20-05-2003,5454223344
Vyom,4,20-05-2009,1223344556
Ankur, 5,20-05-1999,9988776655
Vinod, 6,20-05-1999,9988776655
Vipin,7,20-05-2002,9988776655
Ronak,8,20-05-2007,1223344556
DJ, 9,20-05-2014,9988776655
VJ,10,20-05-2015,9988776655
Sla dit bestand op in dezelfde map als het Python-script. Zodra het bestand aanwezig is, voegt u het volgende codefragment toe aan een Python-bestand:
panda's importeren als pdstudenten = pd.read_csv("studenten.csv")
studenten.hoofd()
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
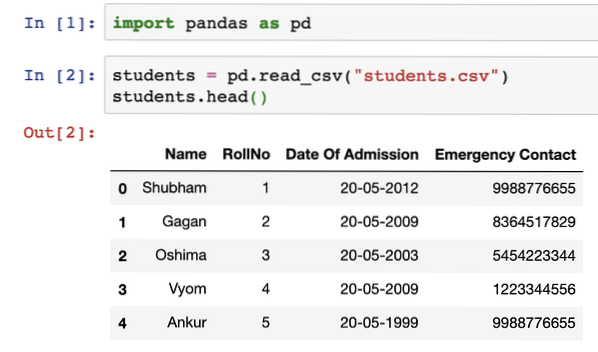
De functie head() in Panda's kan worden gebruikt om een voorbeeld van gegevens in het DataFrame te tonen. Wacht, DataFrame? We zullen in de volgende sectie veel meer over DataFrame bestuderen, maar begrijp gewoon dat een DataFrame een n-dimensionale gegevensstructuur is die kan worden gebruikt om bewerkingen over een reeks gegevens vast te houden en te analyseren of complexe bewerkingen uit te voeren.
We kunnen ook zien hoeveel rijen en kolommen de huidige gegevens hebben:
studenten.vormNadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:

Merk op dat Panda's ook het aantal rijen tellen vanaf 0.
Het is mogelijk om alleen een kolom in een lijst te krijgen met Panda's. Dit kan met behulp van indexeren in Panda's. Laten we eens kijken naar een kort codefragment voor hetzelfde:
student_names = studenten['Naam']student_names
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
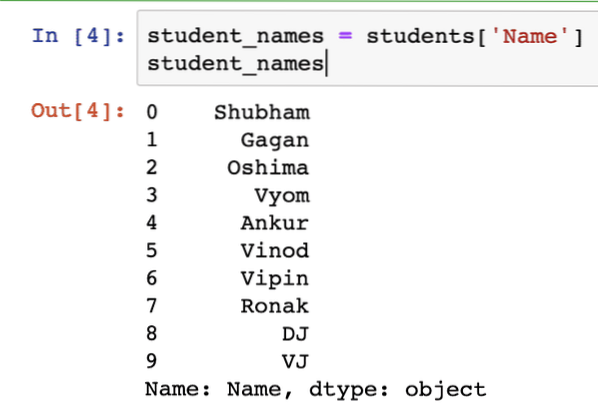
Maar dat ziet er niet uit als een lijst, toch?? Welnu, we moeten expliciet een functie aanroepen om dit object in een lijst te converteren:
student_names = student_names.tolist()student_names
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
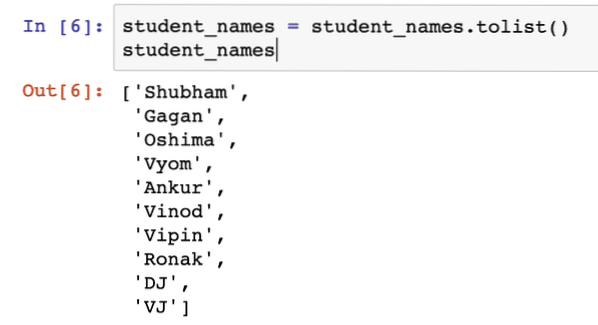
Alleen voor extra informatie kunnen we ervoor zorgen dat elk element in de lijst uniek is en we kiezen alleen niet-lege elementen door enkele eenvoudige controles toe te voegen, zoals:
student_names = studenten['Naam'].dropna().uniek().tolist()In ons geval verandert de uitvoer niet omdat de lijst al geen foutwaarden bevat.
We kunnen ook een DataFrame maken met onbewerkte gegevens en de kolomnamen erbij doorgeven, zoals weergegeven in het volgende codefragment:
mijn_data = pd.DataFrame([
[1, "Chan"],
[2, "Smid"],
[3, "Winslet"]
],
kolommen=["Rang", "Achternaam"]
)
mijn data
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:

Gegevensframes snijden
Het opsplitsen van DataFrames om alleen de geselecteerde rijen en kolommen te extraheren, is een belangrijke functionaliteit om de aandacht te houden voor de vereiste delen van gegevens die we moeten gebruiken. Hiervoor stelt Pandas ons in staat om DataFrame waar en wanneer nodig te segmenteren met uitspraken als:
- iloc[:4,:] - selecteert de eerste 4 rijen en alle kolommen voor die rijen.
- iloc[:,:] - het volledige DataFrame is geselecteerd
- iloc[5:,5:] - rijen vanaf positie 5 en kolommen vanaf positie 5.
- iloc[:,0] - de eerste kolom, en alle rijen voor de kolom.
- iloc[9,:] - de 10e rij, en alle kolommen voor die rij.
In de vorige sectie hebben we het indexeren en segmenteren al gezien met kolomnamen in plaats van de indexen. Het is ook mogelijk om slicen te combineren met indexnummers en kolomnamen. Laten we eens kijken naar een eenvoudig codefragment:
studenten.loc[:5, 'Naam']Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:

Het is mogelijk om meer dan één kolom op te geven:
studenten.loc[:5, ['Naam', 'Contactpersoon voor noodgevallen']]Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
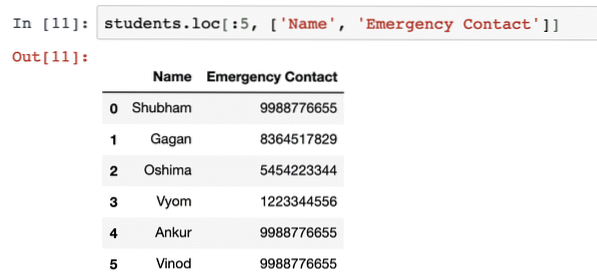
Seriegegevensstructuur in Panda's
Net als Panda's (wat een multidimensionale datastructuur is), is een Series een eendimensionale datastructuur in Panda's. Wanneer we een enkele kolom uit een DataFrame halen, werken we eigenlijk met een serie:
type(studenten["Naam"])Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
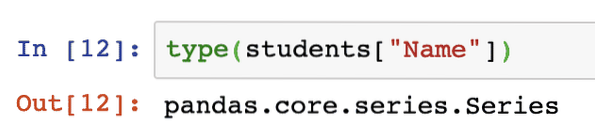
We kunnen ook onze eigen serie maken, hier is een codefragment voor hetzelfde:
serie = pd.Serie([ 'Shubham', 3.7 ])serie
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:

Zoals duidelijk is uit het bovenstaande voorbeeld, kan een reeks ook meerdere gegevenstypen voor dezelfde kolom bevatten.
Booleaanse filters in Panda's DataFrame
Een van de goede dingen in Panda's is hoe het is om gegevens uit een DataFrame te extraheren op basis van een voorwaarde. Zoals het extraheren van studenten alleen als hun rolnummer groter is dan 6:
roll_filter = studenten['RollNo'] > 6roll_filter
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
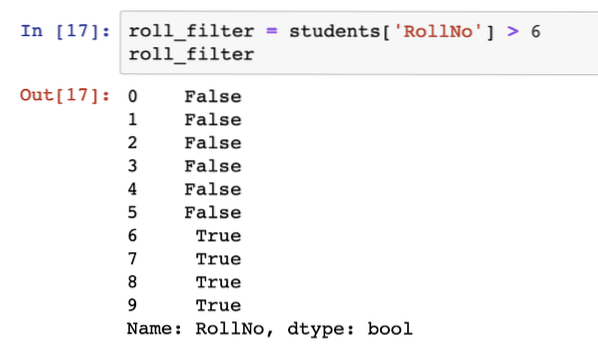
Nou, dat hadden we niet verwacht. Hoewel de uitvoer vrij expliciet is over welke rijen voldeden aan het filter dat we hebben verstrekt, hebben we nog steeds niet de exacte rijen die aan dat filter voldeden. Blijkt dat we kunnen filters gebruiken als DataFrame-indexen ook:
studenten[roll_filter]Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
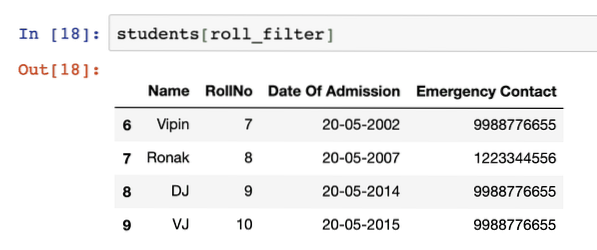
Het is mogelijk om meerdere voorwaarden in een filter te gebruiken zodat de gegevens op één beknopt filter gefilterd kunnen worden, zoals:
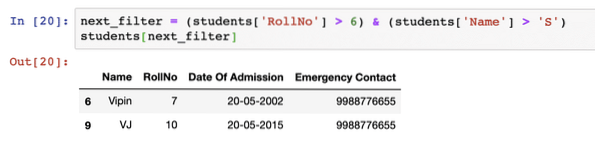
next_filter = (studenten['RollNo'] > 6) & (studenten['Name'] > 'S')studenten[next_filter]
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:
Mediaan berekenen
In een DataFrame kunnen we ook veel wiskundige functies berekenen. We zullen een goed voorbeeld geven van het berekenen van de mediaan. De mediaan wordt berekend voor een datum, niet alleen voor cijfers. Laten we eens kijken naar een kort codefragment voor hetzelfde:
data = studenten['Toelatingsdatum'].astype('datetime64[ns]').kwantiel (.5)datums
Nadat we het bovenstaande codefragment hebben uitgevoerd, zien we de volgende uitvoer:

We hebben dit bereikt door eerst de datumkolom die we hebben te indexeren en vervolgens een gegevenstype aan de kolom te geven, zodat Panda's het correct kunnen afleiden wanneer de kwantielfunctie wordt toegepast om de mediane datum te berekenen.
Conclusie
In deze les hebben we gekeken naar verschillende aspecten van de verwerkingsbibliotheek van Panda's die we met Python kunnen gebruiken om gegevens uit verschillende bronnen te verzamelen in een DataFrame-gegevensstructuur waarmee we op een geavanceerde manier kunnen werken met een dataset. Het stelt ons ook in staat om een subset van gegevens te krijgen waar we tijdelijk aan willen werken en biedt veel wiskundige bewerkingen.
Deel uw feedback over de les op Twitter met @sbmaggarwal en @LinuxHint.


