Met de NumPy-bibliotheek kunnen we verschillende bewerkingen uitvoeren die moeten worden uitgevoerd op gegevensstructuren die vaak worden gebruikt in Machine Learning en Data Science, zoals vectoren, matrices en arrays. We zullen alleen de meest voorkomende bewerkingen met NumPy laten zien die in veel Machine Learning-pijplijnen worden gebruikt. Houd er ten slotte rekening mee dat NumPy slechts een manier is om de bewerkingen uit te voeren, dus de wiskundige bewerkingen die we laten zien, zijn de belangrijkste focus van deze les en niet het NumPy-pakket zelf. Laten we beginnen.
Wat is een vector?
Volgens Google is een vector een grootheid die zowel richting als grootte heeft, vooral om de positie van het ene punt in de ruimte ten opzichte van het andere te bepalen.
Vectoren zijn erg belangrijk in Machine Learning, omdat ze niet alleen de grootte beschrijven, maar ook de richting van de functies. We kunnen een vector maken in NumPy met het volgende codefragment:
importeer numpy als nprij_vector = np.reeks([1,2,3])
print(rij_vector)
In het bovenstaande codefragment hebben we een rijvector gemaakt. We kunnen ook een kolomvector maken als:
importeer numpy als npcol_vector = np.reeks([[1],[2],[3]])
print(col_vector)
Een matrix maken
Een matrix kan eenvoudig worden begrepen als een tweedimensionale array. We kunnen een matrix maken met NumPy door een multidimensionale array te maken:
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])afdrukken (matrix)
Hoewel matrix precies gelijk is aan multidimensionale array, de matrixgegevensstructuur wordt niet aanbevolen om twee redenen:
- De array is de standaard als het gaat om het NumPy-pakket
- De meeste bewerkingen met NumPy retourneren arrays en geen matrix
Een schaarse matrix gebruiken
Ter herinnering: een schaarse matrix is degene waarin de meeste items nul zijn. Een veelvoorkomend scenario bij gegevensverwerking en machine learning is het verwerken van matrices waarin de meeste elementen nul zijn. Overweeg bijvoorbeeld een matrix waarvan de rijen elke video op YouTube beschrijven en de kolommen elke geregistreerde gebruiker vertegenwoordigen. Elke waarde geeft aan of de gebruiker een video heeft bekeken of niet. Natuurlijk zal de meerderheid van de waarden in deze matrix nul zijn. De voordeel met schaarse matrix is dat het niet de waarden opslaat die nul zijn. Dit resulteert in een enorm rekenvoordeel en ook in opslagoptimalisatie.
Laten we hier een vonkmatrix maken:
van scipy import schaarsoriginele_matrix = np.array([[1, 0, 3], [0, 0, 6], [7, 0, 0]])
sparse_matrix = schaars.csr_matrix(originele_matrix)
print(sparse_matrix)
Om te begrijpen hoe de code werkt, zullen we de output hier bekijken:
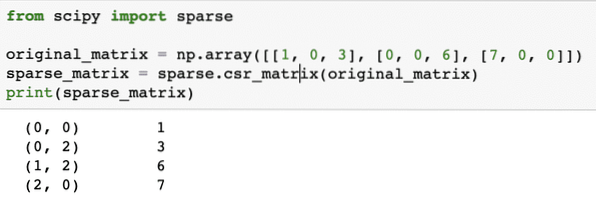
In de bovenstaande code hebben we de functie van een NumPy gebruikt om een te maken Gecomprimeerde dunne rij matrix waarin niet-nul-elementen worden weergegeven met behulp van de op nul gebaseerde indexen. Er zijn verschillende soorten schaarse matrix, zoals:
- Gecomprimeerde dunne kolom
- Lijst met lijsten
- Woordenboek van sleutels
We zullen hier niet in andere schaarse matrices duiken, maar weet dat elk van hun gebruik specifiek is en dat niemand als 'beste' kan worden genoemd.
Bewerkingen toepassen op alle vectorelementen
Het is een veelvoorkomend scenario wanneer we een gemeenschappelijke bewerking moeten toepassen op meerdere vectorelementen. Dit kan worden gedaan door een lambda te definiëren en deze vervolgens te vectoriseren. Laten we eens een codefragment bekijken voor hetzelfde:
matrix = np.reeks([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
mul_5 = lambda x: x * 5
vectorized_mul_5 = np.vectoriseren(mul_5)
vectorized_mul_5(matrix)
Om te begrijpen hoe de code werkt, zullen we de output hier bekijken:

In het bovenstaande codefragment hebben we de vectorize-functie gebruikt die deel uitmaakt van de NumPy-bibliotheek, om een eenvoudige lambda-definitie om te zetten in een functie die elk element van de vector kan verwerken. Het is belangrijk op te merken dat vectoriseren is gewoon een lus over de elementen en het heeft geen effect op de prestaties van het programma. NumPy staat ook toe uitzenden, wat betekent dat we in plaats van de bovenstaande complexe code eenvoudig hadden kunnen doen:
matrix * 5En het resultaat zou precies hetzelfde zijn geweest. Ik wilde eerst het complexe deel laten zien, anders had je de sectie overgeslagen!
Gemiddelde, variantie en standaarddeviatie
Met NumPy is het eenvoudig om bewerkingen uit te voeren met betrekking tot beschrijvende statistieken over vectoren. Het gemiddelde van een vector kan worden berekend als:
np.gemiddelde (matrix)Variantie van een vector kan worden berekend als:
np.var(matrix)De standaarddeviatie van een vector kan worden berekend als:
np.standaard(matrix)De uitvoer van de bovenstaande opdrachten op de gegeven matrix wordt hier gegeven:

Een matrix transponeren
Transponeren is een veel voorkomende bewerking waarover u zult horen wanneer u omringd bent door matrices. Transponeren is slechts een manier om kolom- en rijwaarden van een matrix om te wisselen. Houd er rekening mee dat een vector kan niet worden getransponeerd omdat een vector slechts een verzameling waarden is zonder dat die waarden in rijen en kolommen worden gecategoriseerd. Houd er rekening mee dat het converteren van een rijvector naar een kolomvector niet transponeren is (gebaseerd op de definities van lineaire algebra, wat buiten het bestek van deze les valt).
Voor nu zullen we vrede vinden door een matrix te transponeren. Het is heel eenvoudig om toegang te krijgen tot het transponeren van een matrix met NumPy:
Matrix.TDe uitvoer van het bovenstaande commando op de gegeven matrix wordt hier gegeven:
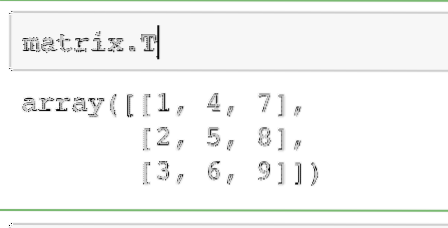
Dezelfde bewerking kan worden uitgevoerd op een rijvector om deze om te zetten in een kolomvector.
Een matrix afvlakken
We kunnen een matrix omzetten in een eendimensionale array als we de elementen ervan op een lineaire manier willen verwerken. Dit kan met het volgende codefragment:
Matrix.afvlakken()De uitvoer van het bovenstaande commando op de gegeven matrix wordt hier gegeven:

Merk op dat de afgeplatte matrix een eendimensionale matrix is, eenvoudigweg lineair in de mode.
Eigenwaarden en eigenvectoren berekenen
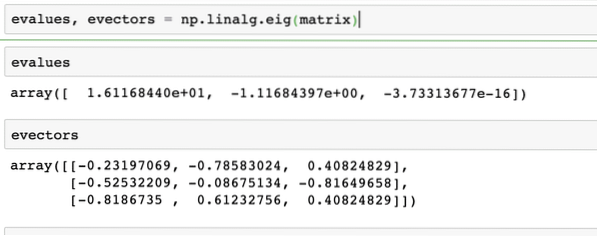
Eigenvectoren worden heel vaak gebruikt in Machine Learning-pakketten. Dus, wanneer een lineaire transformatiefunctie wordt gepresenteerd als een matrix, dan zijn X, Eigenvectoren de vectoren die alleen in schaal van de vector veranderen, maar niet in zijn richting. We kunnen stellen dat:
Xv = vHierbij is X de vierkante matrix en bevat γ de Eigenwaarden. Ook bevat v de eigenvectoren. Met NumPy is het eenvoudig om eigenwaarden en eigenvectoren te berekenen. Hier is het codefragment waar we hetzelfde demonstreren:
evalueert, evectoren = np.linalg.eig(matrix)De uitvoer van het bovenstaande commando op de gegeven matrix wordt hier gegeven:
Puntproducten van vectoren
Dot Products of Vectors is een manier om 2 vectoren te vermenigvuldigen. Het vertelt je over hoeveel van de vectoren zijn in dezelfde richting, in tegenstelling tot het uitwendige product dat u het tegenovergestelde vertelt, hoe weinig de vectoren in dezelfde richting zijn (orthogonaal genoemd). We kunnen het puntproduct van twee vectoren berekenen, zoals aangegeven in het codefragment hier:
a = np.reeks([3, 5, 6])b = np.reeks([23, 15, 1])
np.punt (a, b)
De uitvoer van de bovenstaande opdracht op de gegeven arrays wordt hier gegeven:

Matrices optellen, aftrekken en vermenigvuldigen
Het optellen en aftrekken van meerdere matrices is een vrij eenvoudige bewerking in matrices. Er zijn twee manieren waarop dit kan worden gedaan:. Laten we eens kijken naar het codefragment om deze bewerkingen uit te voeren. Om dit eenvoudig te houden, zullen we dezelfde matrix twee keer gebruiken:
np.toevoegen (matrix, matrix)Vervolgens kunnen twee matrices worden afgetrokken als:
np.aftrekken (matrix, matrix)De uitvoer van het bovenstaande commando op de gegeven matrix wordt hier gegeven:
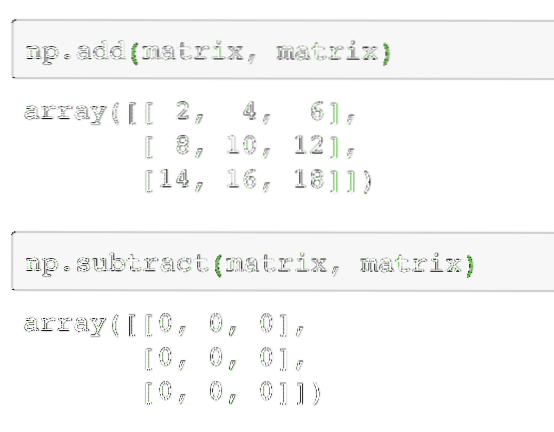
Zoals verwacht wordt elk van de elementen in de matrix opgeteld/afgetrokken met het corresponderende element. Het vermenigvuldigen van een matrix is vergelijkbaar met het vinden van het puntproduct zoals we eerder deden:
np.punt(matrix, matrix)De bovenstaande code vindt de echte vermenigvuldigingswaarde van twee matrices, gegeven als:
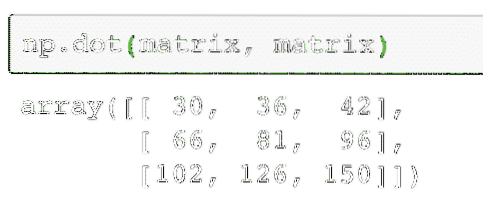
De uitvoer van het bovenstaande commando op de gegeven matrix wordt hier gegeven:

Conclusie
In deze les hebben we veel wiskundige bewerkingen doorlopen met betrekking tot vectoren, matrices en arrays die veel worden gebruikt Gegevensverwerking, beschrijvende statistiek en gegevenswetenschap. Dit was een snelle les die alleen de meest voorkomende en belangrijkste secties van de grote verscheidenheid aan concepten omvatte, maar deze bewerkingen zouden een heel goed idee moeten geven van welke bewerkingen kunnen worden uitgevoerd bij het omgaan met deze gegevensstructuren.
Deel alstublieft uw feedback over de les op Twitter met @linuxhint en @sbmaggarwal (dat ben ik!).


