Gegevenswetenschap
Logistieke regressie in Python
Logistische regressie is een classificatiealgoritme voor machine learning learning. Logistische regressie is ook vergelijkbaar met lineaire regressie....
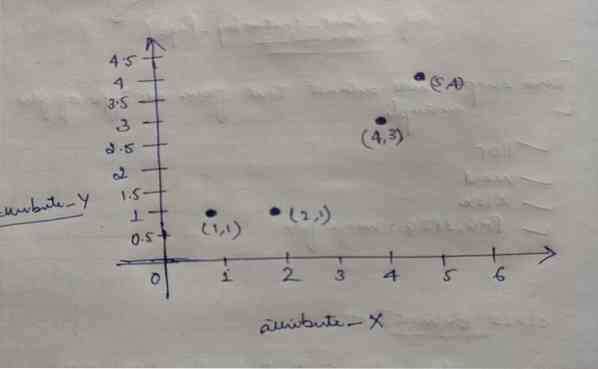
K-betekent clustering
De code voor deze blog, samen met de dataset, is beschikbaar via de volgende link https://github.com/shekharpandey89/k-means K-Means clustering is een...

Een draaitabel maken in Pandas Python
In panda's python bevat de draaitabel sommen, tellingen of aggregatiefuncties die zijn afgeleid van een gegevenstabel. Aggregatiefuncties kunnen worde...
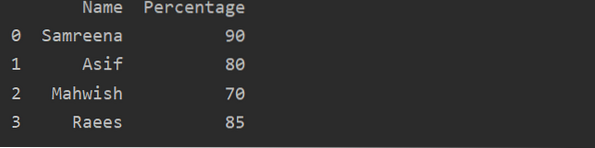
Panda's DataFrame maken in Python?
Panda's DataFrame is een 2D (tweedimensionaal) geannoteerde datastructuur waarin gegevens in tabelvorm worden uitgelijnd met verschillende rijen en ko...
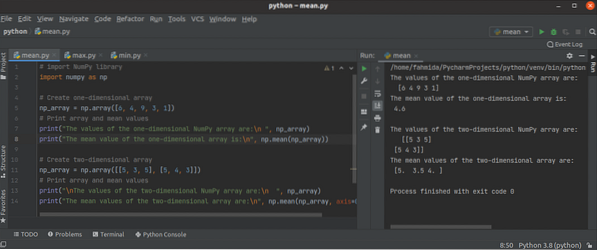
Python NumPy mean(), min() en max() functies gebruiken?
Python NumPy-bibliotheek heeft veel geaggregeerde of statistische functies voor het uitvoeren van verschillende soorten taken met de eendimensionale o...
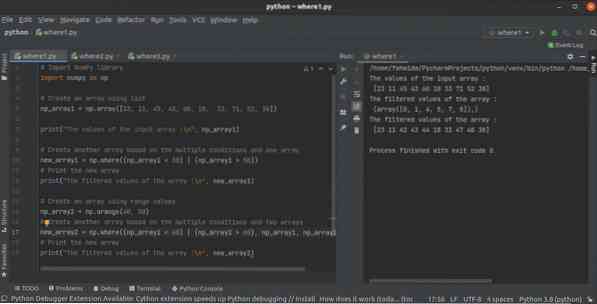
Hoe python NumPy where() functie te gebruiken met meerdere voorwaarden
NumPy-bibliotheek heeft veel functies om de array in python te maken. where() functie is er een van om een array te maken van een andere NumPy array...
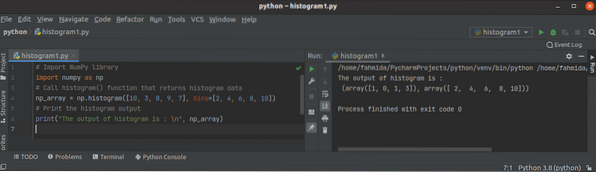
Python NumPy histogram() zelfstudie
Een histogram is een afbeelding van intervallen op frequenties. Het wordt gebruikt om de kansdichtheidsfunctie van de specifieke variabele te benadere...
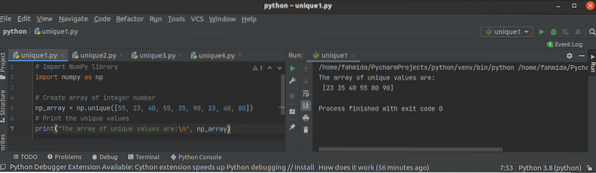
Python NumPy unique()-functie gebruiken
NumPy-bibliotheek wordt in python gebruikt om een of meer dimensionale arrays te maken, en het heeft veel functies om met de array te werken. De fun...
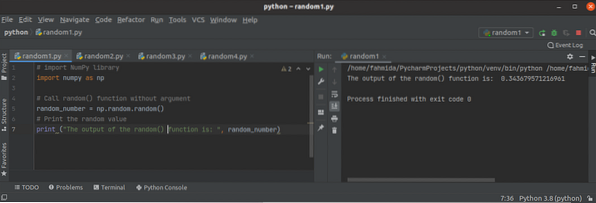
De willekeurige functie Python NumPy gebruiken??
Wanneer de waarde van het getal verandert bij elke uitvoering van het script, wordt dat getal een willekeurig getal genoemd. De willekeurige getallen ...


